随着智算中心(AIDC)的爆发式增长,
传统的网络工程师正迎来一波前所未有的“高薪招聘潮”。
最近翻看各大招聘平台,你会发现无论是大厂、大模型新贵,还是算力云服务商,都在高薪急聘“AI算力网络专家”或“高性能网络运维工程师”。这个岗位的面试动辄就是 30K+ 甚至 50K+ 的薪资,诱惑力十足。
但是,这碗饭可不好吃。传统的数通技能(玩转 BGP、OSPF、堆叠)在智算中心里只能算“基本功”。最近,很多去大厂面试 网络岗位的同学纷纷向我吐槽:“现在的面试官不按套路出牌,进去不问路由协议,直接上来就撕 RDMA、无损网络调优!”
今天,我们就来彻底把这道大厂必考的“分水岭题”拆解透彻,帮你全方位拿下这宝贵的面试分!正好也有学员在群里发了一组面试题,某头部智算公司的真实考题,这个系列我会逐一拆解,本篇先讲第一道 需要更多算力网络面试题的可以在文末联系我们:
单独拎出来今天来拆解一道面试题:
1、从协议栈、流控机制、无损网络实现方式、典型时延/吞吐、大规模运维复杂度五方面对比 IB 和 RoCE,并说明各自适用场景。
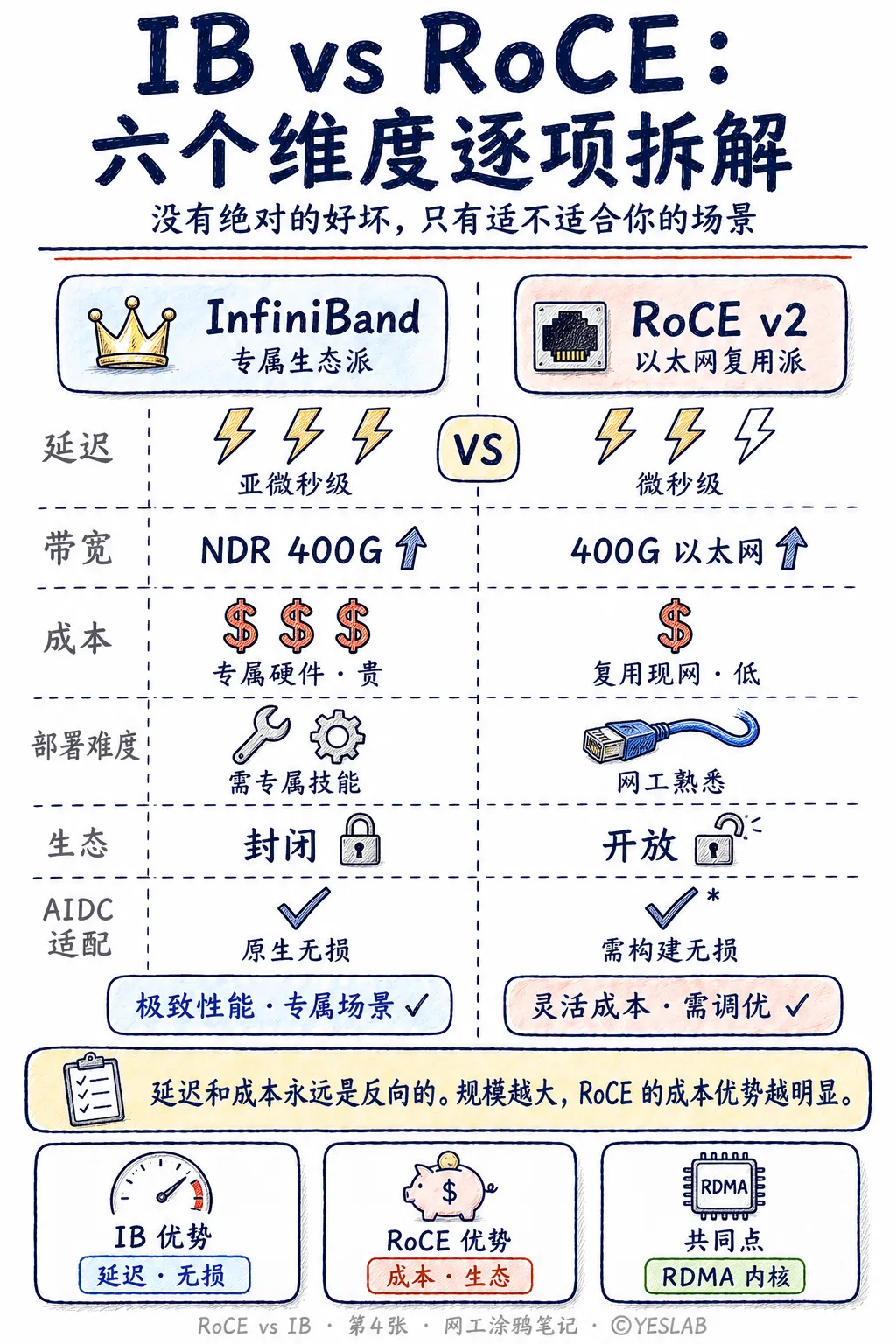
别小看这道题,实际上是一道考你有没有真正理解智算网络底层逻辑的题。答得浅,面试官会继续追问直到你答不上来为止。在 AI 大模型训练、高性能计算(HPC)以及分布式存储的面试中,IB (InfiniBand) 和 RoCE (RDMA over Converged Ethernet) 的对比属于非常核心的硬核技术题。
核心回答框架
“"IB和RoCE都是基于RDMA的高性能网络方案,核心区别在于网络体系和无损保障机制的实现方式不同。IB是专有网络,原生支持RDMA和无损传输,延迟极低但成本高、生态封闭;RoCEv2基于以太网,通过PFC+ECN+DCQCN实现无损网络,成本更低、兼容性更好,但对网络配置和调优要求高。实际选型上,超大规模训练集群对延迟极度敏感的场景更多用IB,中大规模或对成本敏感的场景更多选RoCEv2,国产算力芯片目前也主要适配RoCEv2路线。”
下面从题目要求的五个维度进行深度对比:
1. 协议栈 (Protocol Stack)
- InfiniBand: 采用完全独立的底层网络协议栈。从物理层、链路层、网络层到传输层,全套由 IBTA(InfiniBand Trade Association)定义,彻底抛弃了以太网和 TCP/IP。它是天然的硬件卸载,直接在网卡(HCA)上处理传输层逻辑。
- RoCEv1: 基于以太网链路层,只能在二层(L2)网络中传输,无法跨网段路由(目前已基本淘汰)。
- RoCEv2: 目前的主流。它引入了 UDP/IP 封装,将 RDMA 报文作为 UDP 载荷(固定目的端口 4791),从而具备了三层(L3)路由能力,能够兼容标准的以太网交换机和路由器。
2. 流控机制 (Flow Control)
- InfiniBand: 采用 基于 Credit(信变/凭证)的逐跳(Hop-by-Hop)流控机制。接收端会根据自身 Buffer 大小向发送端发放 Credit,发送端没有 Credit 就绝对不会发包。这种硬限流机制在底层物理层和链路层就保证了永远不会因为网络拥塞而丢包。
- RoCEv2: 传统以太网是“尽力而为(Best-effort)”的丢包网络,为了实现 RDMA,RoCEv2 必须依靠一套组合拳:
- PFC(Priority-based Flow Control,基于优先级的反压): 在二层通过发送 PAUSE 帧来阻止对端发送,防止交换机队列溢出。但 PFC 容易引发死锁(Deadlock)和反压风暴。
- ECN(Explicit Congestion Notification)与 DCQCN: 在三层利用 IP 头部的 ECN 标记网络拥塞。结合 DCQCN 算法,让接收端通知发送端主动降速。它是端到端的慢速调节,反应比 IB 慢。
3. 无损网络实现方式 (Lossless Implementation)
- InfiniBand:天然无损。 无损是 IB 协议栈根植于骨子里的特性。通过硬件级 Credit 流控方案,配合其特有的自适应路由(Adaptive Routing,AR),网络在极高负载下也能保持绝对无损且不会出现局部热点。
- RoCE:人工调校的“准无损”。 RoCE 必须高度依赖“PFC + ECN/DCQCN”的精细化配置。交换机必须严格划分队列(Queue),配置复杂的 PFC 水位线(XON/XOFF 阈值)以及 ECN 触发门限。一旦配置失误,就会退化为丢包网络,导致 RDMA 大量重传,性能雪崩。
4. 典型时延与吞吐 (Latency & Throughput)
- IB 具有绝对优势。因为协议栈极度精简且全硬件化,单跳交换机时延通常在 100ns - 300ns 级别,端到端时延通常 < 1us。
- RoCEv2 受到以太网交换机架构的限制,单跳交换机时延一般在 400ns - 1us 左右,且在大规模拥塞时,由于端到端降速机制的延迟,长尾时延(Tail Latency)会明显恶化。
- 两者目前在单端口速率上都在并驾齐驱(如 200G、400G、800G)。但在多链路聚合和整体网络利用率上,IB 依靠自适应路由技术,带宽利用率可达 95% 以上;而 RoCE 受限于以太网的 ECMP(等价多路径)哈希冲突,整体带宽利用率通常在 70% - 80% 左右。
5. 大规模运维复杂度 (O&M Complexity)
- 管理集中化: IB 网络必须依赖一个核心组件——子网管理器(Subnet Manager, SM)。SM 负责计算全网拓扑、分配本地标识(LID)和下发路由表。
- 运维痛点: 属于私有生态(长期由 Mellanox/NVIDIA 主导),技术封闭。当集群规模达到数万卡时,SM 的计算瓶颈和主备切换可能成为单点故障风险。此外,测试和排障工具不通用,高级运维人员稀缺。
- 管理去中心化: 采用传统以太网的分布式路由协议(如 BGP),扩展性极强,支持数十万节点的超大规模集群。
- 运维痛点: 极度依赖“网络黑盒调优”。PFC 死锁、PFC 风暴、不合理的多路径哈希导致的拥塞极难排查。需要运维团队具备极高水平的 INT(带内网络遥测)和自动化网络监控能力。
总结与对比矩阵
| | |
|---|
| 协议生态 | | |
| 无损保证 | | |
| 时延性能 | | |
| 带宽利用率 | 高(可达 95%+, 靠 Adaptive Routing) | |
| 规模与运维 | | |
| 综合成本 | | |
各自适用场景:
- 极致性能导向的千卡/万卡级 AI 超大模型训练: 如 GPT-4 级别的千亿/万亿参数大模型,算力对网络时延、稳定性和多卡并行效率(All-Reduce)极度敏感。
- 传统科学计算(HPC): 气象预报、石油勘探、分子动力学模拟等强耦合场景。
- 预算充足且追求开箱即用的团队: 宁可支付高昂的硬件溢价,也不愿在网络调优和长尾时延排查上浪费时间的场景。
- 超大规模公有云/互联网数据中心: 节点数动辄几万甚至几十万,需要统一以太网架构,且具备极强的 BGP 网络运维团队。
- 中小型 AI 微调(Fine-tuning)或推理(Inference)集群: 对时延要求没有超大模型预训练那么严苛,RoCE 的性价比更高。
- 高性能分布式存储(如 NVMe-oF): 存储流量相对规整,通过合理的以太网 VLAN 划分和 QoS 配置可以获得极佳的性价比。
💡 面试官加分提示:在回答的最后,可以顺便提一句:“目前业界为了解决 RoCE 的哈希冲突和 IB 的封闭生态,正在大力推进 UALink 和 Ultra Ethernet Consortium (UEC,超以太网联盟) 标准,试图在以太网之上实现类似 IB 的自适应路由和全硬件拥塞控制,这是未来高性能网络的一个重要趋势。”
本期福利
整理了一份「智算中心网络工程师25道高频面试题」,覆盖无损网络、GPU集群通信、架构设计、运维监控、前沿方向五个模块。 这是目前智算岗位里,面试官问的比较多的,帮大家整理好了

回复「智算面试题」,获取更多面试题。
后续我们抽空也会逐一拆解
技术浪潮奔涌向前,风口不会等人。
无论你是网络工程的初学者,还是希望提升技能的专业人士,YESLAB致力于提供系统化的技术学习资源。通过灵活的学习模式和实战案例解析,帮助你逐步构建专业知识体系,探索职业发展的可能性。加入YESLAB,与行业爱好者共同成长,如需了解更多学习资源,可联系课程顾问获取,开启你的技术进阶之旅!