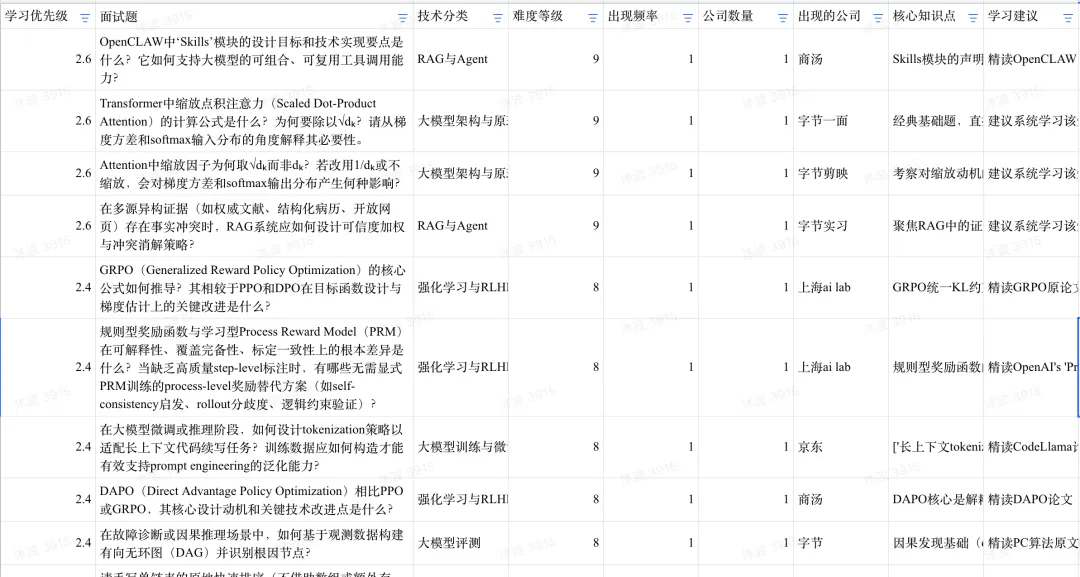
一、面试题在变"刁钻",但不是为了刁难
早些年问 LoRA(其实也就是两年年前吧),是问"什么是 LoRA、它怎么省显存";后来变成"为什么 A 矩阵要零初始化";这一个月我看到的问法已经是"如果你在 QKV 三个线性层用了不同秩的 LoRA,会引发什么兼容性问题"。同样是 LoRA,问的层次完全不一样了。
这种问法很难靠背书应付。它逼着你在一个具体的设计选择和它的反面之间做权衡判断,而权衡这件事本身没有标准答案。我看到一道题问"在已经用 GRPO 做完在线偏好优化之后,是否还有必要补一轮离线 DPO"——这种问题,论文里查不到,博客里也写不出来,你只有真的在现场调过模型、踩过对应的坑,才会本能地知道这两个方法对偏好数据的假设根本不在同一个层面上。
我自己的体会是,面试官想看的已经不是知识面,而是技术品味。知识可以恶补,品味只能通过长时间的真实工程沉淀出来。所以这一阶段的面试越来越像一场气味鉴定——三两个追问下来,对面是真的做过还是只是听过,藏不住。
二、RLHF 已经从"加分项"变成了"操作系统课"
这一个月的题里,对齐相关的内容多到几乎每家大厂都在反复盘问 DPO、PPO、GRPO 这些名字。
我觉得这个现象挺值得品的。前两年大家拼命卷预训练,谁能把模型训出来谁就赢了。现在所有人手里都有了能跑的模型,问题就转移到了"怎么让它真的好用"——而这恰恰是对齐的事。对齐从来不是一个一次性动作,它是一整套需要在工程现场反复权衡的方法论:奖励函数会被钻空子、偏好数据会漂移、SFT 之后有些能力会退化、KL 约束的强度直接决定收敛性……每一个环节都是坑。
所以当一家公司在面试里反复追问这些细节,背后大概率是他们的业务里已经被这些坑收拾过了。他们想招的,是一个能在下次踩坑时帮他们爬出来的人。
如果你正在准备这个方向,我的建议是:别只记结论。"DPO 不需要 reward model"这种话每个候选人都会说,但你能讲清楚 DPO 为什么能把 RLHF 简化成一个监督学习问题、它隐含的偏好建模假设是什么、在哪些数据分布下这个假设会崩——这才是真正能让面试官眼睛一亮的东西。
三、RAG 的题在悄悄换味道
RAG 相关的题量也很大,但味道跟 RLHF 完全不同。RLHF 的题偏数学和理论,RAG 的题几乎全是工程现场——
检索召回了正确片段但答案还是错的,问题出在哪?多个证据源相互冲突时怎么决定信谁?对话历史太长要压缩,怎么保证不丢关键的需求锚点?
这种问法很说明问题。它意味着 RAG 在工业界已经过了"搭一个 demo"的阶段,进入了"在生产环境里持续出问题、需要持续诊断"的阶段。面试官真正在确认的,是你有没有在一个真实跑着的 RAG 系统里调过 bug。
我自己有过这种经历,所以特别能理解这种问法的杀伤力。一个跑在线上的 RAG 系统出了 bad case,你打开 trace 看到检索结果其实没问题、prompt 也没问题、模型也不算笨,但答案就是错的——这种时候你会发现,所有教科书都没告诉你下一步该往哪查。Failure 可能出在 reranker 的打分偏好、可能出在 chunk 边界正好切散了语义、可能只是 prompt 里某个词激活了错误先验。这种诊断直觉是教不出来的,只能在事故里磨出来。
所以如果你简历上写了 RAG 项目,提前想好这几件事:你的 chunk size 为什么定这个值、上线前后哪个指标变化最大、最棘手的一个 bad case 是怎么定位的、最后怎么改的。这些细节,比你说"做过一个 RAG 系统准确率 85%"有用一百倍。
四、一个反直觉的现象:基础题在回归
这个月的题里有件挺让我意外的事——Transformer 注意力机制、KL 散度、batch size 影响这些"老题",反而出现得比想象中频繁。
但仔细看问法又不一样了。现在不会让你写 attention 公式,而是问你"为什么除以 √dₖ 而不是 dₖ,如果改成 1/dₖ 会怎样"。这是在问你对这个公式背后梯度方差和 softmax 输入分布的物理理解。
我觉得这个回归挺值得玩味的。前几年大模型热潮里,整个行业都有点被"大模型"三个字晃花了眼,以为这是个全新的领域,得用全新的知识体系。冷静下来才发现,绝大多数所谓的"大模型问题",根子上还是优化、概率、表示学习这些经典问题,只是规模放大之后表现出了新的形态。
面试官们也意识到了这一点,所以开始用基础题筛人——当工具越来越成熟、上手门槛越来越低,能区分候选人的反而是最古老的东西:你对线性代数有没有手感,你看到一个梯度公式能不能立刻判断它的数值稳定性,你写过的那点训练代码里有没有沉淀出真实的数学直觉。
这件事对求职者其实是个好消息。它意味着踏踏实实把基础学好的人,红利期反而来了。
五、评测题的兴起,是我觉得最重要的信号
前面几个趋势都算是延续,但"大模型评测"题量的上升,是一个真正的新东西。
这背后的逻辑很有意思。当所有人都开始用 LLM-as-a-Judge 打分、用 RLHF 对齐人类偏好之后,"裁判本身可不可信"就成了一个绕不过去的问题。Swap consistency、rubric 设计、正交消融——这些题目背后其实是同一个焦虑:我们怎么知道我们的优化是真的优化,而不是在某个有偏的评测体系里自欺欺人?
我个人非常欣赏这个方向的兴起。它代表了一种元能力的考察——你不光要会做,还得会判断"做得到底有没有用"。在一个所有人都能调出还不错效果的时代,能设计出可信评测体系的人,是真正稀缺的。
六、几个藏在题目里的弦外之音
还有几个不太显眼但值得说的信号。
多模态题没我想象中那么多。 这跟外界对多模态的关注度不太匹配。我猜真实情况是,多模态目前还集中在少数几家有视觉基础的大厂里实战,大部分公司即使在做也没到能拿出来面试的成熟度。所以如果你做多模态,反而要警惕:招聘市场上的真实需求可能比表面热度小很多,要慎重选择目标公司。
手撕代码依然是入场券。 经典内容没什么变化,但有个细节值得注意——现在的题越来越倾向考"原生实现",比如不调 sum 怎么实现 N 维数组沿 axis 求和。这考的是你对底层数据流动的真实理解,不是 API 熟练度。这块没什么策略可言,就是日常练。
系统设计题在悄悄变多。 库存扣减、消息队列幂等、MySQL 和 Redis 一致性——这些后端题在大模型岗里出现频率明显上升。大厂在招大模型工程师的时候,越来越期望你不光懂模型、还懂工程系统。纯算法背景的同学要警惕,单点深度可能已经撑不过现在的面试节奏了。
最后想说一件事
把这一个月的题翻完之后,我最强烈的感受是:这个领域的面试已经过了"信息差红利期"。
前几年你看几篇博客、刷几个 repo、面熟几个名词,就能在面试里讲得头头是道。现在不行了。当面试官随便一个追问就能戳穿你的边界,靠"看过"撑不起一场技术对话。
我自己面试别人的时候有个小习惯——一个候选人讲完他做过的项目,我会问一句"如果让你重做,你会改哪里"。这一个问题就能把人分成两层:有些人会沉默,有些人会立刻给出三五个具体的改进点和它们各自的代价。
后者是真正在思考的人。这种人不需要把面试题背得滚瓜烂熟,他们的思考方式就是面试官想要的答案。
所以如果你正在准备面试,与其多刷十道题,不如针对你简历上的每一个项目,逼自己问出五个最尖锐的反问。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
