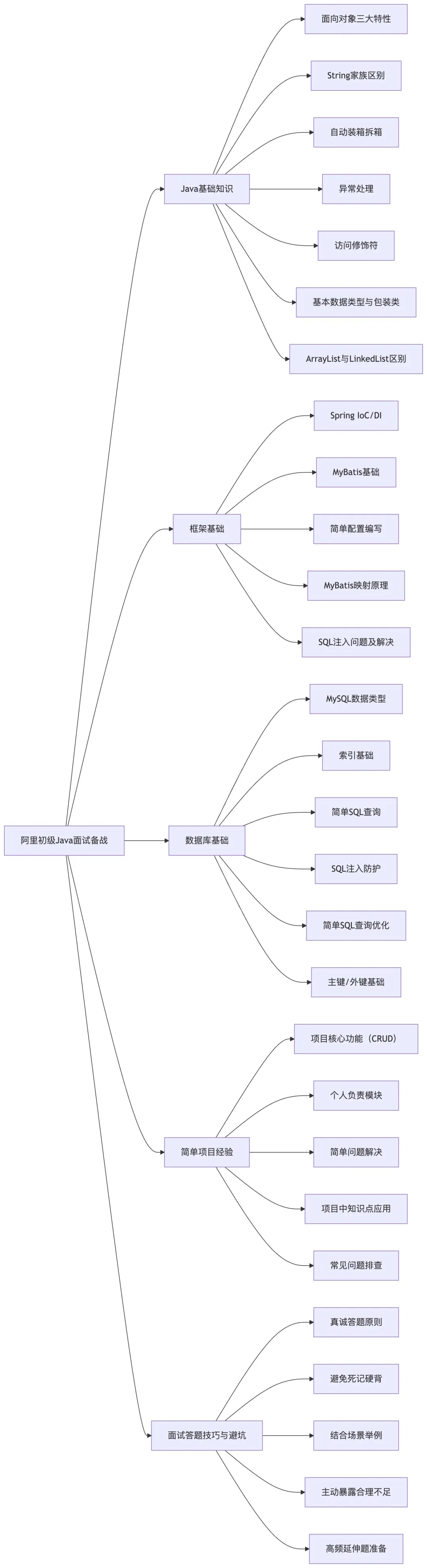
我(小张),应届生,计算机专业本科,有 1 年 Java 课程设计 + 实习经验(主要做简单电商后台 CRUD 开发),熟悉 Spring、MyBatis 基础用法,了解 MySQL 基本操作,近期参加了阿里 Java 初级开发岗位(适配应届生 / 1-2 年经验)的面试。全程复盘这次面试,重点拆解初级岗位高频基础题、答题陷阱、实用技巧,完全贴合应届生和刚入行 1-2 年开发者的认知水平,不涉及复杂高并发、分布式深层方案,主打 “基础扎实、逻辑清晰、踩坑避雷”,希望能帮到和我一样刚起步的小伙伴。
阿里初级 Java 开发,核心对接淘宝 / 天猫业务线的基础开发模块(如商品基础信息管理、订单简单操作、后台数据统计等),不涉及核心高并发、分布式架构设计,重点考察 “Java 基础是否扎实、是否具备基本的开发思维、学习能力和复盘意识”。准备阶段不用贪多求深,我按照备战核心模块梳理了完整的复盘内容,结构如下:
一、Java 基础知识(面试核心,占比 60% 以上)
Java 基础知识是阿里初级面试的重中之重,优先掌握以下核心知识点,不背定义、结合场景理解,是得分关键。
1.1 面向对象三大特性
面向对象三大特性是 Java 开发的核心思想,贯穿实体类设计、接口实现全流程,也是面试必考题,核心应用场景完全贴合初级开发实际:
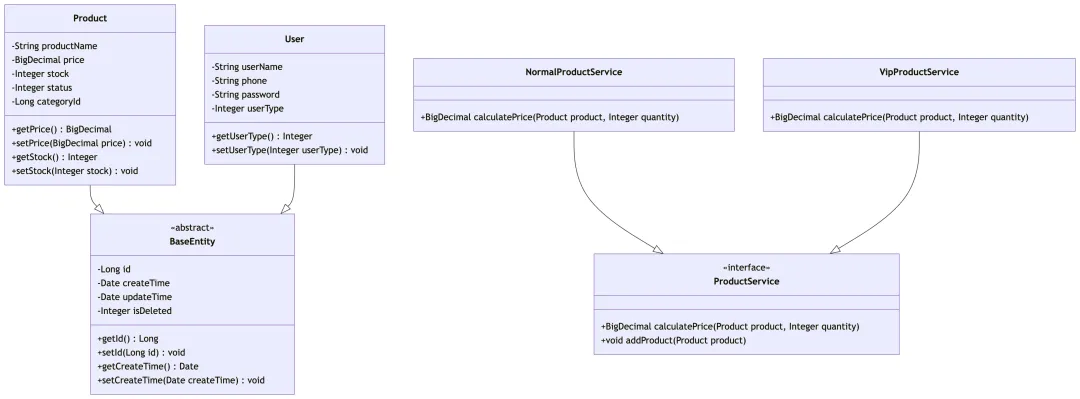
- 1. 封装:将对象的属性和方法捆绑在一起,隐藏内部细节,只对外提供公共访问接口,保证数据安全。例如设计商品实体类Product,将 id、名称、价格等属性用private修饰,通过public的 getter/setter 方法访问修改,同时在 setter 方法中添加校验(如价格不能为负数),避免非法数据输入。
- 2. 继承:子类继承父类的属性和方法,减少代码冗余,实现代码复用。例如设计父类BaseEntity,封装所有实体类(Product、User)共有的 id、创建时间、修改时间,让Product类继承该父类,无需重复编写相同属性和方法,这是初级开发中继承最常用的场景。需注意:Java 只能单继承,不能多继承。
- 3. 多态:同一方法在不同子类中有不同实现,调用时根据实际对象执行对应方法,提升代码灵活性。例如设计商品服务接口ProductService,定义addProduct、getProduct等核心方法,实现NormalProductService(普通商品处理)、VipProductService(会员商品处理)两个子类,重写价格计算方法,调用时用父类引用接收子类对象,后续新增商品类型无需修改原有代码。
为了更直观理解三大特性在项目中的落地关系,我整理了校园二手电商项目的核心类图:
注:类图中 BaseEntity 体现了继承的复用性,Product 类的 private 属性 + public 方法体现了封装,两个实现类重写 calculatePrice 方法体现了多态
1.2 String、StringBuffer、StringBuilder 的区别与使用场景
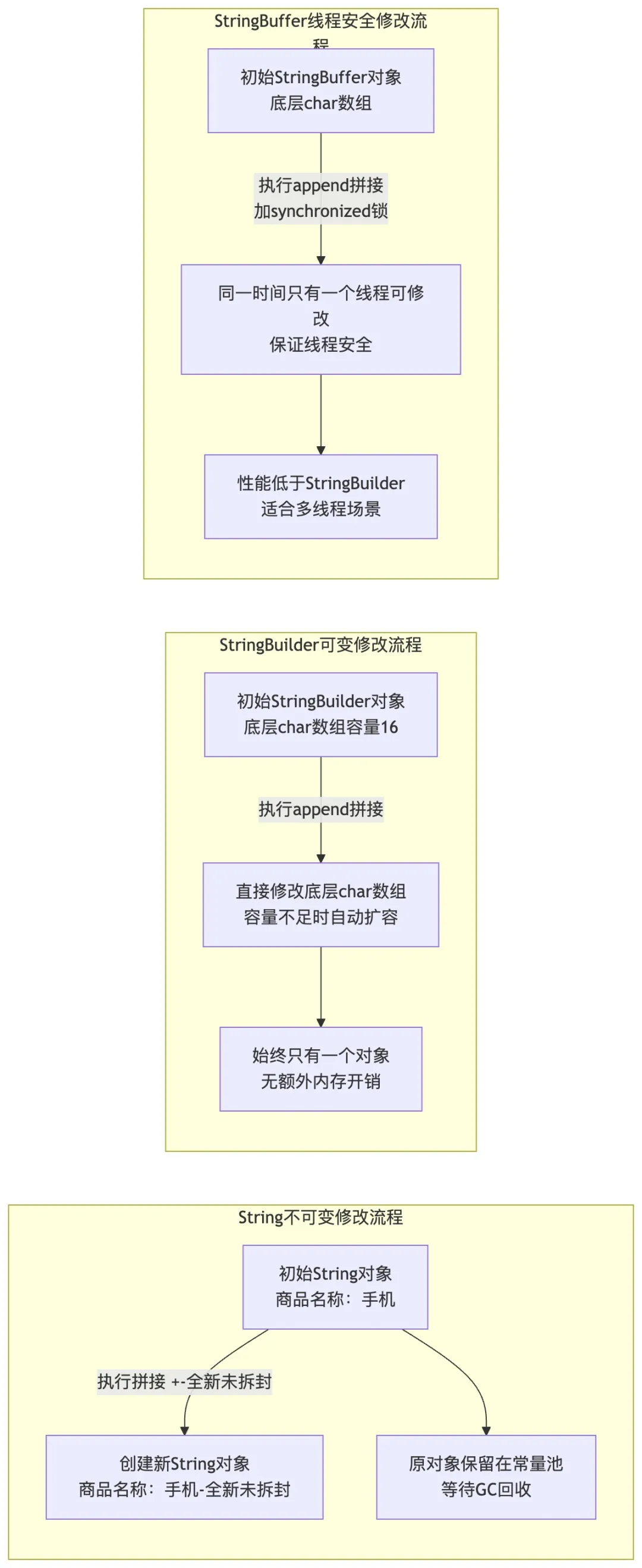
核心区别围绕 “不可变性、线程安全、性能” 三个维度,结合初级开发中字符串存储、拼接场景选择,避免踩坑:
- 1. String:不可变(底层是 final 修饰的字符数组),一旦创建无法修改,修改时会创建新对象。适合字符串不频繁修改的场景,如定义常量、接收前端固定字符串(如 “操作成功” 提示语)。
- 2. StringBuffer:可变,方法加synchronized修饰,线程安全,但性能较差。初级项目多为单线程,几乎不用,仅需了解多线程场景下的应用。
- 3. StringBuilder:可变,无线程安全修饰,性能优于 StringBuffer。适合单线程下频繁拼接字符串的场景,如拼接 SQL 语句、用户提示信息,是初级开发中最常用的字符串拼接工具。
为了更清晰理解三者修改字符串时的底层差异,我整理了内存操作流程图:
1.3 自动装箱与拆箱
Java 5 之后的特性,编译器自动完成基本数据类型与对应包装类的转换,无需手动调用方法,重点规避 NPE 陷阱:
- 1. 自动装箱:基本数据类型→包装类,如Integer i = 10,编译器自动转换为Integer.valueOf(10),常见于接收前端参数、属性赋值场景。
- 2. 自动拆箱:包装类→基本数据类型,如int j = i,编译器自动转换为i.intValue(),常见于运算、方法参数传递场景。
- 3. 触发场景与陷阱:赋值、方法参数传递、运算时都会触发;最常见的坑是包装类为 null 时直接拆箱,会报NullPointerException(NPE),需先判空再拆箱(如接收前端库存参数时,先判断是否为 null,再赋值运算)。
为了直观展示装箱拆箱的触发流程和 NPE 陷阱,我整理了执行流程图:
1.4 异常处理机制:Checked 与 Unchecked Exception
通过 try、catch、finally、throw、throws 实现,目的是捕获异常、避免程序崩溃,同时方便排查问题,核心区分两种异常的处理方式:
- 1. Checked Exception(编译时异常):编译时强制处理,不处理无法通过编译,如IOException(文件读取)、SQLException(数据库连接)。处理方式:try-catch 捕获(打印异常信息,返回友好提示)或 throws 声明,抛给上层方法处理。
- 2. Unchecked Exception(运行时异常):编译时不检查,运行时出现,多由代码逻辑错误导致,如NullPointerException(空指针)、ArrayIndexOutOfBoundsException(数组越界)、IllegalArgumentException(参数异常)。处理方式:优先用 if 条件规避(如判空),或针对性捕获,避免用catch (Exception e)捕获所有异常,掩盖具体问题。
首先整理 Java 异常体系的完整结构类图,清晰区分两类异常:
再补充异常处理的核心执行流程图,明确 try-catch-finally 的执行逻辑:
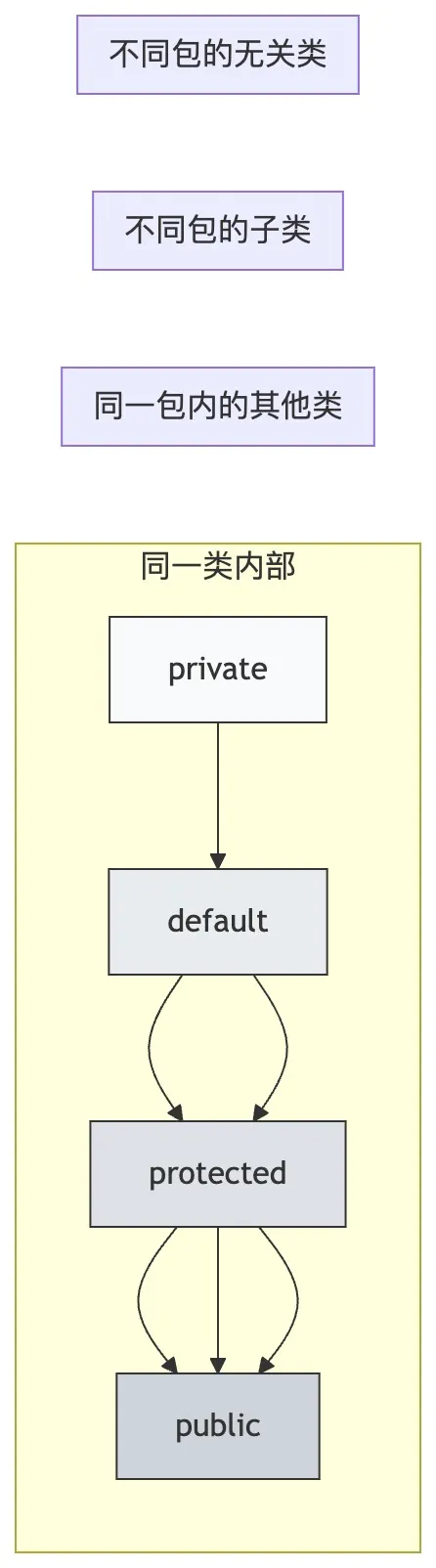
1.5 Java 访问修饰符
Java 共 4 种访问修饰符,按权限从大到小为 public、protected、default(无修饰符)、private,核心用于控制方法和属性的访问权限,保证数据安全、遵循最小权限原则:
| 访问修饰符 | 作用范围 |
| public | 所有地方可见(同一类、同一包、不同包的类、不同包的子类) |
| protected | 同一类、同一包的类、不同包的子类可见 |
| default(无修饰符) | 同一类、同一包的类可见,不同包的类(包括子类)不可见 |
| private | 只有同一类可见,其他地方都不可见 |
初级开发常用场景:实体类属性用 private 修饰,getter/setter 方法、对外提供的 Service/Controller 方法用 public 修饰;内部工具方法用 private 修饰,不同包子类需调用的方法用 protected 修饰;避免使用 default 修饰符,防止访问权限混乱。
为了更直观展示 4 种修饰符的权限范围,我整理了可见范围示意图:
注:箭头指向代表权限包含关系,越靠右权限范围越大
1.6 基本数据类型与包装类
核心区别及实际应用场景,是面试延伸题高频考点:
- 1. 核心区别:以 int 和 Integer 为例,int 是基本数据类型,无 null 值,默认值 0;Integer 是包装类(对象),有 null 值,默认值 null。
- 2. 实际应用:int 可直接运算,Integer 需拆箱为 int 才能运算;实际开发中,接收前端参数用 Integer(避免前端传 null 时报错),运算时用 int(提前判空,规避 NPE 陷阱)。
结合日常开发的标准流程,整理了基本类型与包装类的使用规范流程图:
1.7 ArrayList 与 LinkedList 的区别及使用场景
两者均为 List 接口实现类,核心区别在于底层实现和性能,需根据场景选择,是初级开发中集合使用的基础:
- 1. 底层实现:ArrayList 底层是动态数组(可自动扩容),LinkedList 底层是双向链表(每个元素有前驱和后继节点)。
- 2. 性能区别:ArrayList 查询快(通过索引直接访问,时间复杂度 O (1)),增删慢(需移动后续元素);LinkedList 增删快(修改节点指针,无需移动元素),查询慢(需遍历链表,时间复杂度 O (n))。
- 3. 使用场景与技巧:查询多、增删少(如商品列表查询)用 ArrayList;增删多、查询少(如库存为 0 商品筛选、用户列表维护)用 LinkedList。补充技巧:ArrayList 默认初始容量 10,已知元素数量时提前设置容量,避免自动扩容带来的性能损耗。
首先整理两者底层数据结构的对比示意图:
再补充两者核心操作的性能对比流程图,清晰展示不同场景的选择逻辑:
二、框架基础(初级开发必备,面试高频延伸考点)
对于初级开发,阿里不会深挖框架源码,重点考察 “会不会用、懂不懂核心作用、能不能规避基础坑”,核心围绕 Spring 和 MyBatis 两大常用框架,贴合 CRUD 开发场景。
2.1 Spring IoC 与 DI 核心概念
这是 Spring 的核心,面试必问,不用背复杂定义,结合开发场景讲清楚即可:
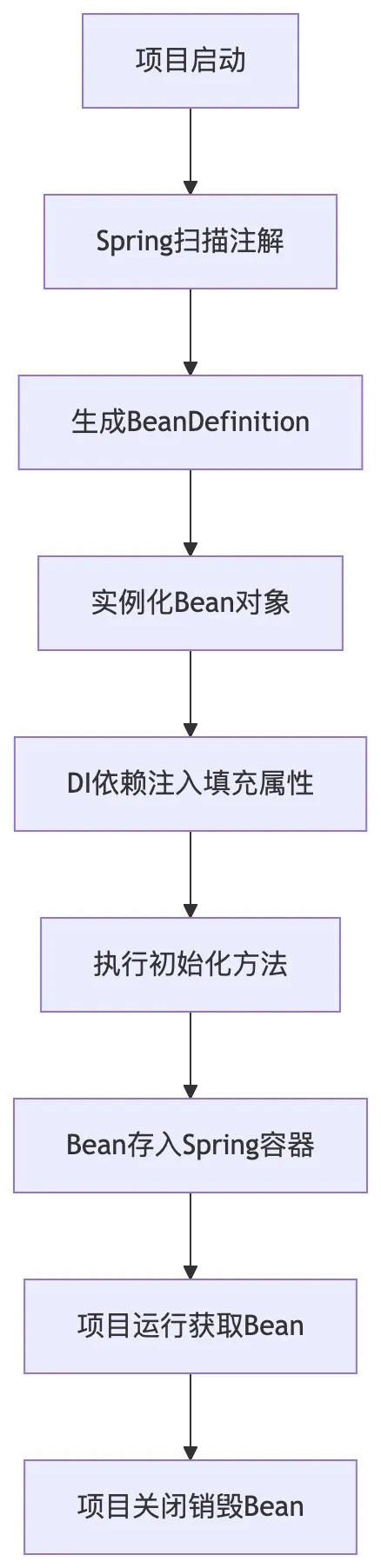
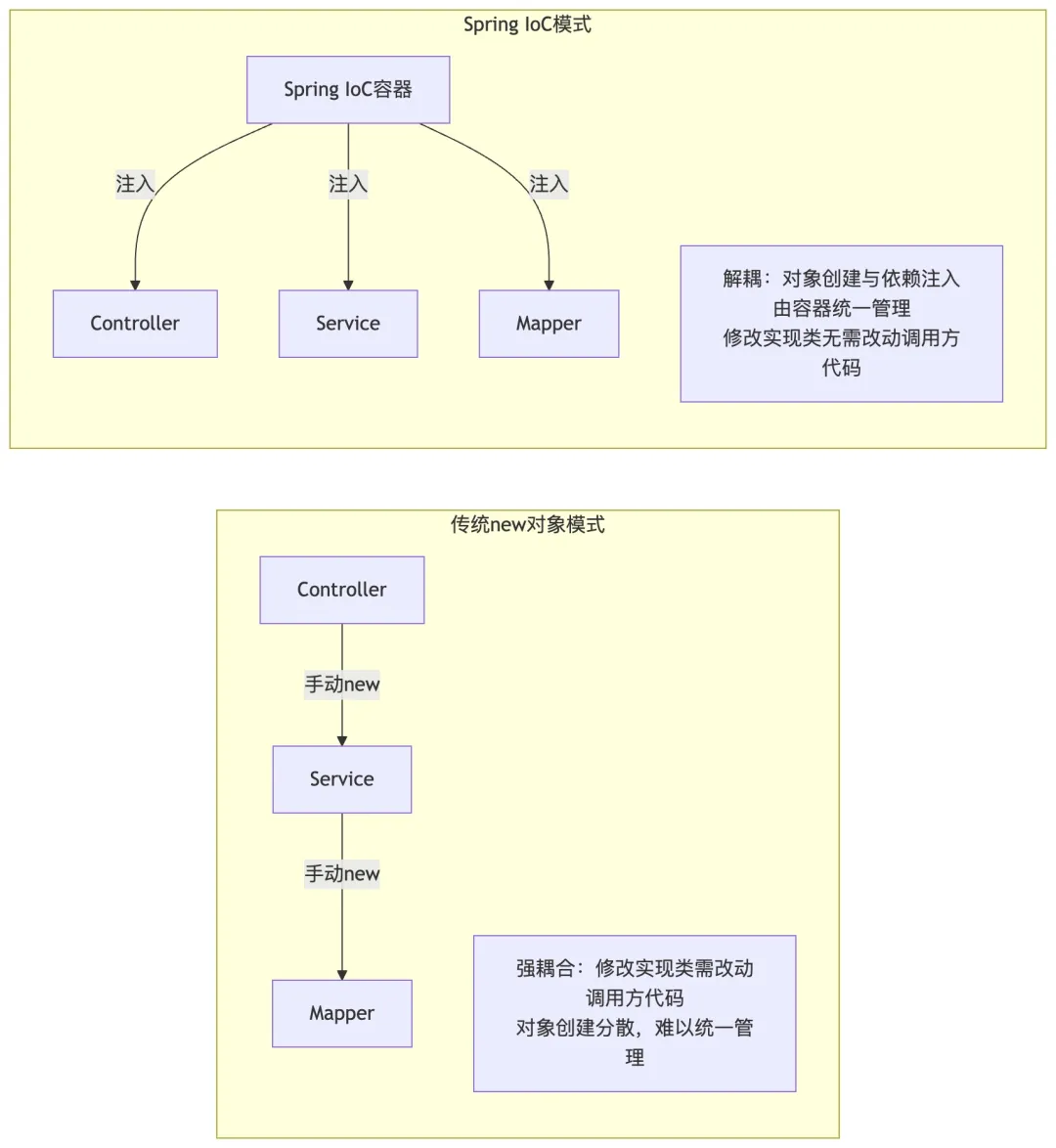
- 1. IoC(控制反转):原本我们创建对象需要自己new ProductService(),现在把对象的创建、生命周期管理全部交给 Spring 容器来做,控制权从开发者手里反转到了 Spring 容器,这就是控制反转。核心作用是解耦,不用在代码里硬编码创建对象,修改实现类时不用改动调用方代码。
- 2. DI(依赖注入):是 IoC 的具体实现方式,简单说就是 Spring 把对象需要的依赖自动赋值进去,不用我们手动 set。比如在ProductController里,用@Autowired注解注入ProductService,不用自己写productService = new ProductService(),Spring 会自动把容器里的对应对象注入进来。
- 3. 初级开发常用场景:Controller、Service、Mapper 层的类,都用@Controller、@Service、@Mapper注解交给 Spring 容器管理,通过注解注入依赖,不用手动创建对象,这是我们日常 CRUD 开发最常用的用法。
为了直观理解 IoC 容器的完整工作流程,整理了 Spring Bean 生命周期与依赖注入流程图:
同时补充传统开发模式与 IoC 模式的对比流程图,更清晰体现核心优势:
2.2 MyBatis 基础用法与核心优势
MyBatis 是初级开发必用的持久层框架,阿里重点考察基础用法和和 JDBC 的区别:
- 1. 核心作用:封装了 JDBC 的繁琐操作,不用我们手动注册驱动、创建连接、编写 Statement、处理结果集,只需要关注 SQL 语句本身,把 SQL 和 Java 代码解耦。
- 2. 基础用法:核心分为三层,Mapper 接口(定义数据操作方法)、Mapper.xml 文件(编写对应 SQL 语句)、实体类(映射数据库表字段)。比如ProductMapper接口里定义List<Product> selectProductByCategoryId(Long categoryId)方法,在对应的 XML 文件里写查询 SQL,MyBatis 会自动完成接口方法和 SQL 的绑定,执行后把结果映射成 Product 对象返回。
- 3. 核心优势:SQL 完全由开发者控制,灵活度高,适合复杂业务查询;支持动态 SQL,可根据参数拼接不同的 SQL 语句,比如商品多条件查询时,用<if>标签判断参数是否为空,动态拼接查询条件,这是日常开发最常用的功能。
整理 MyBatis 核心执行全流程图,覆盖从接口调用到结果返回的完整链路:
2.3 MyBatis 映射实现原理
初级开发不用深挖源码,讲清楚核心逻辑即可,这是面试高频延伸题:
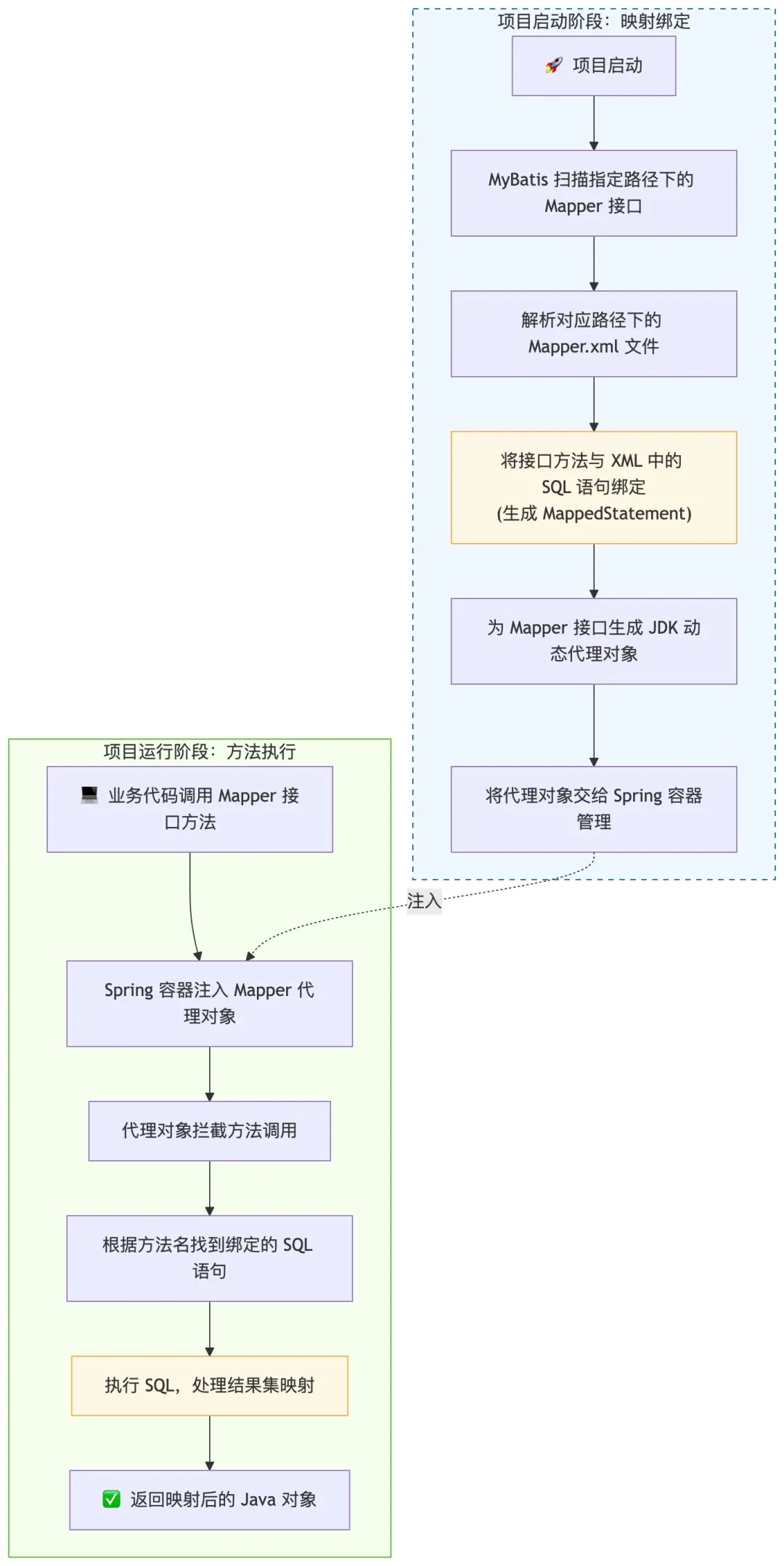
- 1. 项目启动时,MyBatis 会扫描指定路径下的 Mapper 接口和对应的 XML 文件,把接口方法和 XML 里的 SQL 语句绑定起来,生成 Mapper 接口的代理对象。
- 2. 我们调用 Mapper 接口的方法时,实际调用的是代理对象,代理对象会根据方法找到对应的 SQL 语句,交给 JDBC 去执行。
- 3. SQL 执行完成后,MyBatis 会根据接口方法的返回值类型,把数据库查询的结果集自动映射成 Java 对象,比如把查询到的商品表数据,自动映射成 Product 实体类的对象,字段名和属性名对应即可完成映射,不用我们手动从 ResultSet 里取值赋值。
结合项目启动和运行两个阶段,整理 MyBatis 映射原理的完整流程图:
2.4 SQL 注入问题及 MyBatis 中的解决方案
这是初级开发面试必问的安全题,也是日常开发必须规避的坑:
- 1. 什么是 SQL 注入:用户输入的参数里包含恶意 SQL 片段,拼接到执行的 SQL 里,导致执行了非预期的恶意操作,比如用户在商品名称查询框里输入' or 1=1 --,拼接后的 SQL 会查询出全表的商品数据,甚至删除、修改数据。
- 2. MyBatis 的解决方案:核心是区分#{} 和${}的用法:
- #{} :预编译处理,MyBatis 会把 SQL 里的#{} 替换成?占位符,调用 JDBC 的 PreparedStatement 的 set 方法赋值,参数会被当成字符串处理,不会执行里面的 SQL 片段,从根本上避免 SQL 注入,日常开发 99% 的场景都应该用#{} 。
- ${}:字符串直接替换,会把参数原封不动的拼接到 SQL 里,有 SQL 注入风险,只有极少数场景能用,比如需要动态传入表名、排序字段的时候,必须严格校验参数内容,避免注入。
整理 SQL 注入攻击流程与 MyBatis 防护方案的对比流程图:
2.5 基础配置编写规范
初级开发不用写复杂配置,但要掌握核心配置的作用和规范,这是阿里考察开发规范的重点:
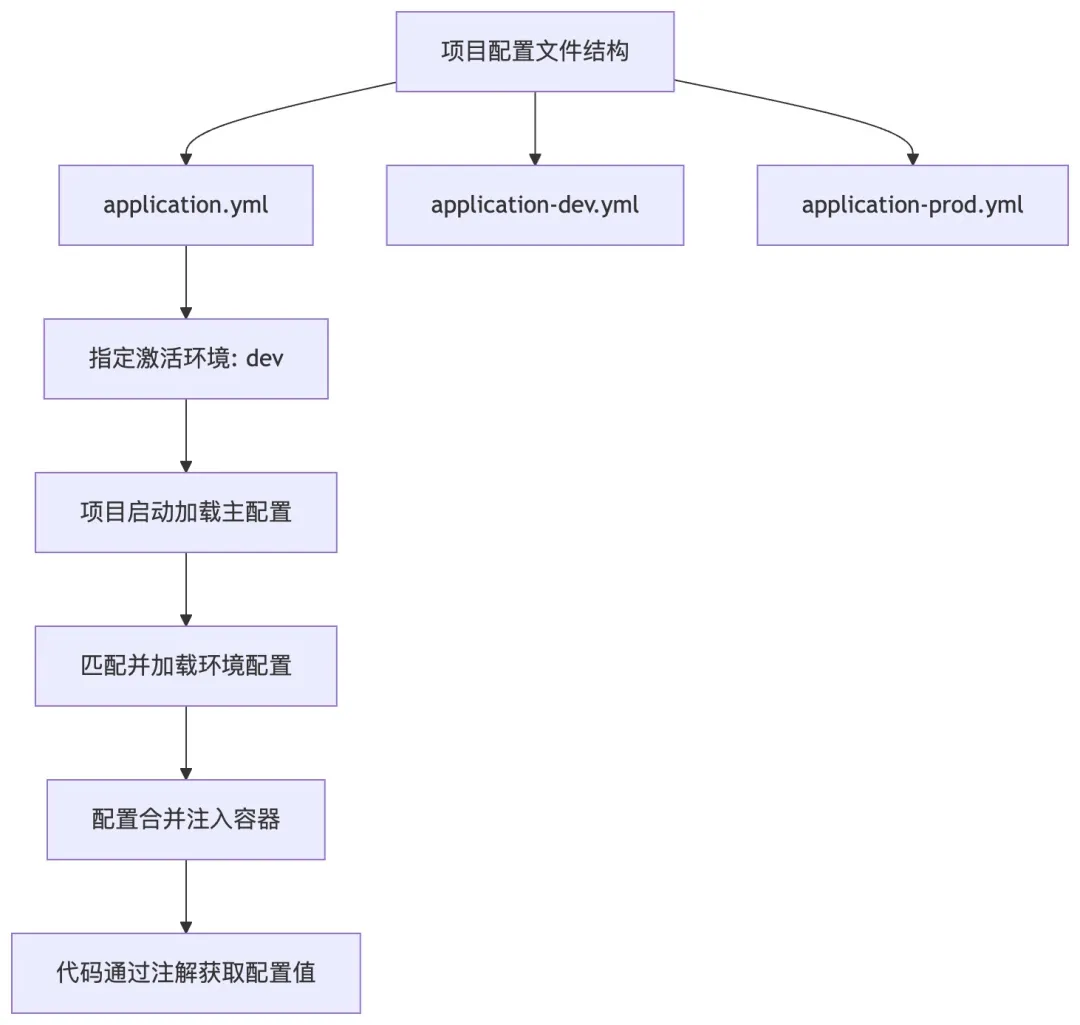
- 1. Spring 配置规范:核心配置用 application.yml/application.properties,不用把配置硬编码在代码里,比如端口号、数据库连接信息、文件上传路径等,都写在配置文件里,通过@Value注解或@ConfigurationProperties注入到代码里,不同环境(开发、测试、生产)用不同的配置文件,避免环境配置混乱。
- 2. MyBatis 配置规范:开启驼峰命名自动转换(数据库下划线命名和 Java 驼峰命名自动映射,比如product_name自动映射productName),不用手动写别名映射;Mapper.xml 文件和 Mapper 接口放在同一路径下,包名保持一致,避免找不到映射文件;禁止在 XML 里写过于复杂的嵌套 SQL,降低可读性和维护性。
整理 Spring 多环境配置管理与加载流程图:
三、数据库基础(CRUD 开发核心,面试必问)
初级开发的核心工作就是和数据库打交道,阿里重点考察基础规范、SQL 编写能力、简单优化和安全防护,不深挖复杂的索引原理和分库分表方案。
3.1 MySQL 常用数据类型选择规范
数据类型选择是开发的基础,也是面试高频题,核心原则是 “够用就好,精准匹配”,结合电商场景讲常用规范:
- 1. 整数类型:主键 ID 用BIGINT(不用 INT,避免数据量超过上限);状态、数量等小数值用TINYINT或INT,比如商品上下架状态用TINYINT(0 下架,1 上架),不用字符串存储。
- 2. 字符串类型:固定长度的内容用CHAR,比如手机号固定 11 位用CHAR(11);长度不固定的内容用VARCHAR,比如商品名称、用户昵称,根据实际长度设置上限,不要统一用VARCHAR(255);大文本内容(比如商品详情)用TEXT,不用 VARCHAR。
- 3. 小数类型:价格、金额等对精度要求高的字段,必须用DECIMAL,比如商品价格用DECIMAL(10,2),绝对不能用FLOAT或DOUBLE,会有精度丢失的问题,导致价格计算错误。
- 4. 时间类型:创建时间、修改时间用DATETIME,不用TIMESTAMP(有时间范围上限),开发中统一设置创建时间自动填充、修改时间自动更新,不用代码里手动赋值。
结合电商开发场景,整理了数据类型选择决策流程图,开发时可直接参考:
3.2 主键与外键基础
- 1. 主键基础:主键是表中唯一标识一条数据的字段,必须非空、唯一。阿里开发规范要求,所有表必须有主键,推荐用自增BIGINT作为主键,不用 UUID、字符串作为主键(性能差、占用空间大);不推荐用联合主键,降低可读性和索引效率。
- 2. 外键基础:外键用来关联两张表,比如订单表的用户 ID 关联用户表的主键 ID。初级开发需要了解外键的作用,但阿里规范不推荐在数据库里使用物理外键,推荐用逻辑外键(代码里控制关联关系),避免物理外键带来的锁冲突、数据维护麻烦的问题,比如删除用户数据时,物理外键会校验订单表是否有相关数据,导致删除失败,而逻辑外键可以在代码里灵活控制。
整理物理外键与逻辑外键的对比与选择流程图:
3.3 索引基础原理与使用场景
索引是 SQL 优化的核心,初级开发不用深挖 B + 树原理,掌握基础用法和场景即可:
- 1. 什么是索引:索引是帮助数据库快速查询数据的一种数据结构,相当于书的目录,不用翻完整本书就能找到想要的内容,能大幅提升查询效率,缺点是会降低增删改的效率(需要同步更新索引),同时占用额外的存储空间。
- 主键索引:主键自动创建的索引,唯一且非空,性能最好。
- 普通索引:给单个查询频繁的字段创建的索引,比如商品分类 ID、用户手机号。
- 唯一索引:字段值唯一的索引,比如用户手机号、订单编号,保证数据唯一性,同时提升查询效率。
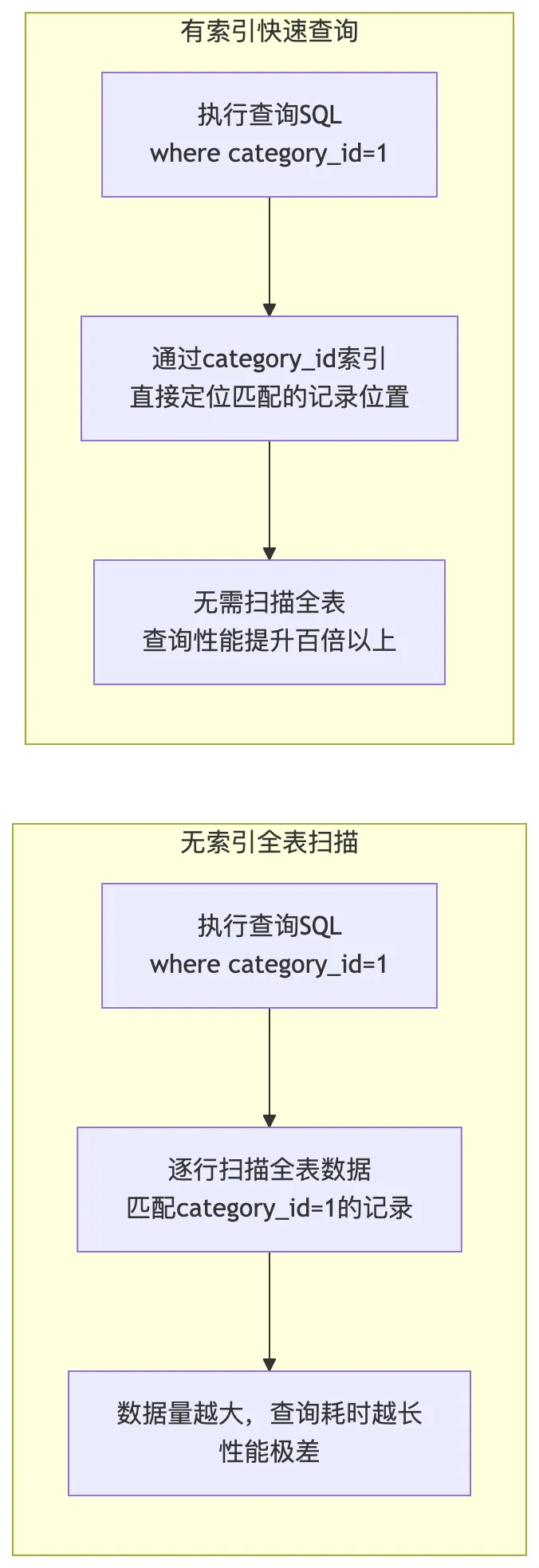
- 3. 初级开发使用规范:查询频繁的字段才建索引,不要给所有字段都建索引;区分度低的字段不要建索引,比如商品状态(只有 0 和 1 两个值),建了索引也不会生效;查询时尽量用索引字段作为 where 条件,避免全表扫描。
首先整理索引查询与全表扫描的性能对比流程图:
再补充索引创建的决策流程图,帮助初级开发判断要不要建索引:
3.4 基础 SQL 查询编写规范
阿里对 SQL 编写规范要求很高,初级开发必须掌握,避免写出低效、难维护的 SQL:
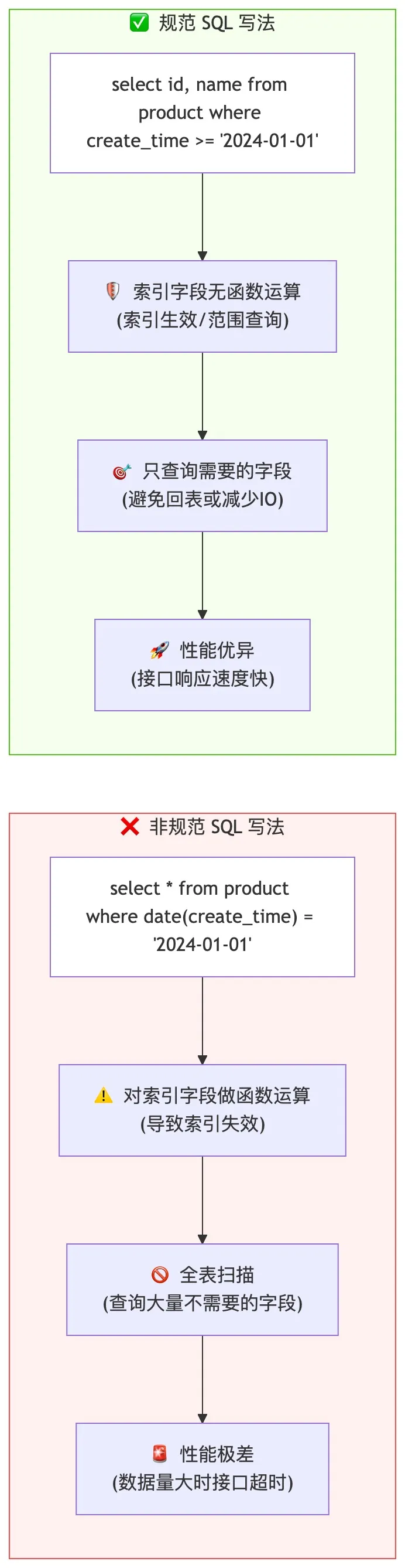
- 1. 禁止使用select *查询,必须指定具体的字段名,只查询需要的字段,减少数据传输,同时避免索引失效。
- 2. 查询必须加 where 条件,避免全表扫描,哪怕是查询所有数据,也要加where is_deleted=0的逻辑删除条件。
- 3. 避免在 where 条件里对索引字段做函数运算、类型转换,会导致索引失效,比如where date(create_time) = '2024-01-01',会导致 create_time 的索引失效。
- 4. 多表关联查询时,关联字段的类型必须一致,且都要有索引,避免关联查询时全表扫描;关联表数量尽量不超过 3 张,对于初级开发,复杂查询可以拆成多次单表查询,降低 SQL 复杂度。
整理规范 SQL 与非规范 SQL 的执行效果对比流程图:
3.5 SQL 注入防护核心方法
除了 MyBatis 的#{} 预编译,初级开发还要掌握基础的防护方法:
- 1. 核心原则:永远不要相信用户的输入,所有前端传入的参数都要做校验,比如商品分类 ID 必须是数字,不能包含特殊字符。
- 2. 禁止直接拼接 SQL 语句,不管是 MyBatis 里的${},还是代码里用字符串拼接 SQL,都有注入风险,必须用预编译的方式处理参数。
- 3. 最小权限原则:数据库账号只给必要的权限,不给删表、改表结构的权限,哪怕出现注入,也能降低损失。
整理 SQL 注入全链路防护流程图,覆盖从前端到数据库的完整防护体系:
3.6 简单 SQL 查询优化技巧
初级开发不用做复杂的 SQL 优化,掌握这几个基础技巧,就能解决 90% 的慢查询问题:
- 1. 优先给 where 条件、关联条件、排序字段建合适的索引,避免全表扫描,这是最有效的优化方式。
- 2. 用explain关键字查看 SQL 的执行计划,判断索引是否生效,比如explain select * from product where category_id = 1,看 type 字段是否是 range、ref,避免出现 ALL(全表扫描)。
- 3. 避免用like '%xxx%'前置模糊查询,会导致索引失效,比如查询商品名称包含 “手机” 的商品,like '%手机%'不会走索引,like '手机%'可以走索引。
- 4. 限制查询结果的数量,比如商品列表查询必须加分页,用limit限制每次查询的条数,避免一次性查询大量数据,导致内存溢出。
结合我在项目中遇到的慢查询问题,整理了慢查询优化的标准排查流程图:
四、简单项目经验梳理(应届生面试加分项)
对于应届生和初级开发,阿里不会要求你有复杂的大型项目经验,重点看你有没有把学到的知识点用到实际开发里,有没有解决问题的能力和复盘意识。我结合自己的实习电商项目,梳理了面试时的讲解思路,完全贴合初级开发的水平。
4.1 项目核心功能(CRUD)
我做的项目是校园二手电商后台管理系统,核心就是基础的 CRUD 功能,没有复杂的高并发、分布式架构,完全是初级开发的真实场景:
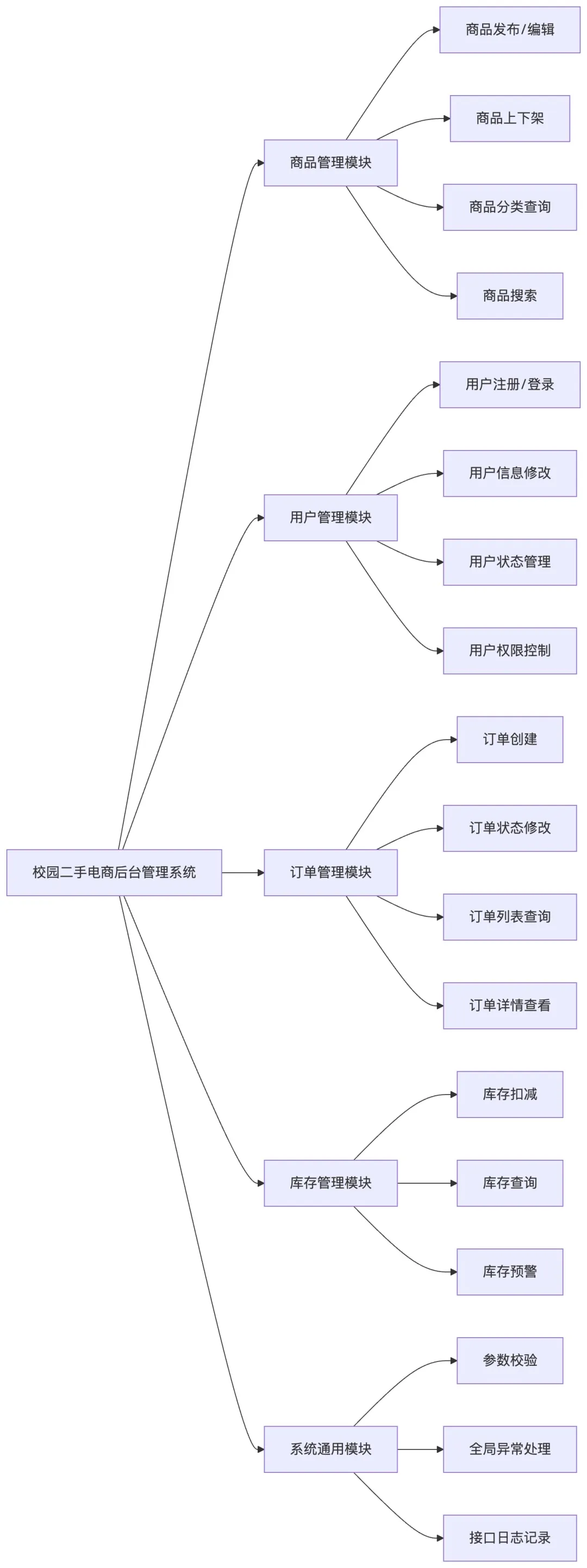
- 核心业务模块:商品管理(发布、上下架、分类查询)、用户管理(注册、信息修改、状态管理)、订单管理(创建、状态修改、查询)、简单的库存管理。
- 技术栈:SpringBoot + MyBatis + MySQL,前端用简单的 Vue 管理系统模板,我只负责后端接口开发,全部是 Restful 风格的接口,完成基础的增删改查功能。
- 项目规模:单服务部署,没有微服务拆分,数据库共 6 张表,单表最大数据量不到 1 万条,完全是初级开发能 hold 住的规模。
整理校园二手电商系统的整体模块架构图:
4.2 个人负责模块拆解
面试时不用讲整个项目,重点讲自己负责的模块,说清楚自己做了什么,不要夸大:
- 我全程负责商品管理模块的后端开发,包括商品实体类设计、Mapper 层、Service 层、Controller 层的全部代码,完成了商品的增删改查、分页查询、分类筛选、上下架状态修改的全部接口。
- 参与了用户管理模块的部分开发,负责用户信息查询、状态修改的接口,以及参数校验、异常处理的通用代码。
- 配合测试同学做接口联调,修复了接口空指针、参数校验不通过、SQL 查询结果错误等 bug,完成了接口文档的编写。
整理我负责的商品管理模块的分层架构流程图,贴合 CRUD 开发的标准流程:
4.3 项目中知识点的落地应用
这是面试的重点,阿里想通过项目看你对基础知识点的理解,而不是只会复制粘贴代码,我在面试时重点讲了这几个点:
- 1. 面向对象思想的落地:设计Product实体类,用 private 修饰属性,public 的 getter/setter 方法访问,实现了封装;设计了BaseEntity父类,封装了 id、创建时间、修改时间、逻辑删除字段,所有实体类都继承这个父类,复用了代码,用到了继承;设计了通用的BaseService接口,不同模块的 Service 实现类重写对应的方法,用到了多态。
- 2. 基础类的正确使用:商品列表查询用 ArrayList 存储返回结果;动态拼接 SQL 查询条件用 StringBuilder,不用 String 拼接,避免创建大量临时对象;接收前端的商品数量、价格参数用包装类 Integer、BigDecimal,运算时先判空再拆箱,避免了 NPE 问题。
- 3. 异常处理规范:用全局异常处理器统一处理异常,业务异常(比如商品不存在、库存不足)抛出自定义的业务异常,用 try-catch 针对性捕获,不会用一个大的 Exception 捕获所有异常,同时打印完整的异常日志,方便排查问题。
- 4. 框架和数据库的规范使用:Service、Controller 层的类都交给 Spring 容器管理,用 @Autowired 注入依赖,不用手动创建对象;MyBatis 的 Mapper.xml 里全部用 #{} 传递参数,避免 SQL 注入;给商品表的分类 ID、名称字段建了普通索引,查询时避免全表扫描,用 explain 验证过索引生效。
整理知识点从学习到项目落地的映射关系图,面试时可以直接参考这个逻辑讲解:
4.4 开发中遇到的简单问题与解决方法
面试时讲自己遇到的问题和解决方法,比只讲功能更能打动面试官,不用讲复杂的线上故障,初级开发的真实小问题就足够:
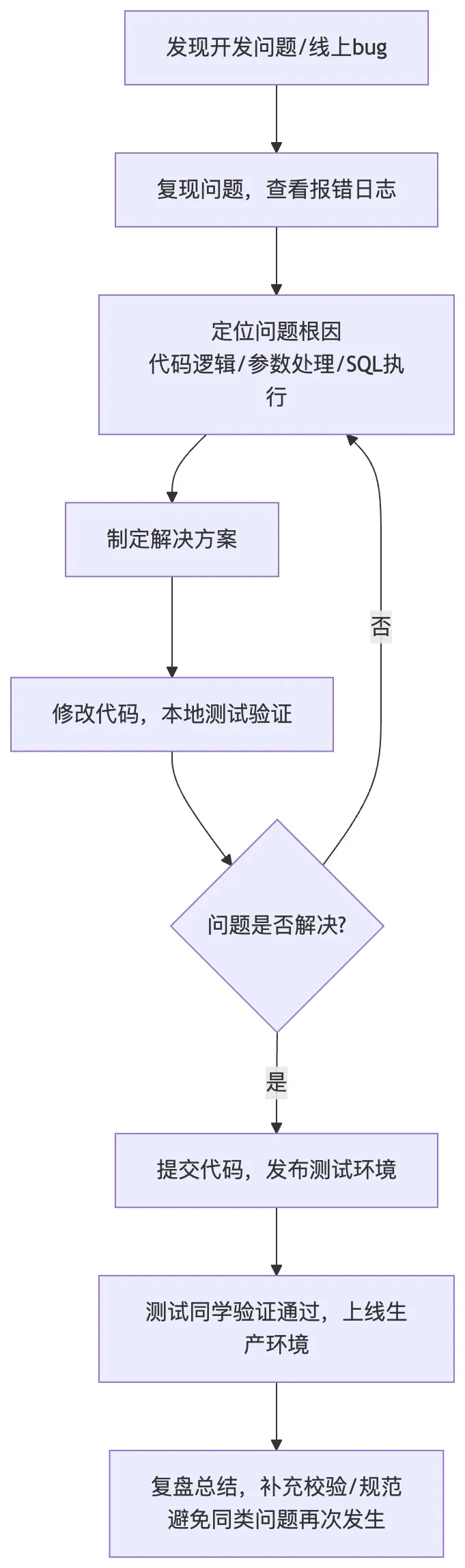
- 场景:前端传入的商品分类 ID 为 null 时,查询 SQL 执行报错,后续运算也出现 NPE。
- 解决方法:在 Controller 层和 Service 层都加了参数校验,用 if 判断必填参数是否为 null,为空直接返回参数错误的提示;给实体类的包装类属性设置默认值,避免拆箱时 NPE;在全局异常处理器里针对 NPE 做了友好提示,同时打印日志定位问题位置。
- 场景:商品数据量到 5000 条左右时,分页查询接口响应时间超过 1 秒。
- 解决方法:用 explain 查看执行计划,发现查询没有走索引,全表扫描;给 where 条件里的分类 ID、上下架状态字段建了联合索引,同时把 select * 改成了只查需要的字段,优化后接口响应时间降到了 100ms 以内。
- 场景:前端传入的价格是 19.9,更新到数据库后变成了 19.8999999999。
- 解决方法:把数据库里的价格字段从 DOUBLE 改成了 DECIMAL (10,2),Java 实体类里的属性从 Double 改成了 BigDecimal,同时在 setter 方法里加了精度校验,彻底解决了精度丢失的问题。
结合这三个典型问题,整理了开发问题排查与解决的通用闭环流程图:
4.5 常见问题排查思路
阿里很看重初级开发的排查问题能力,哪怕是简单的问题,有清晰的排查思路,就比只会找导师帮忙的候选人强很多,我总结了日常开发的基础排查思路:
- 1. 接口报错排查:先看控制台的异常日志,定位报错的类和具体行数,看异常类型(NPE、数组越界、SQL 执行错误),针对性排查;如果是 SQL 报错,把 MyBatis 打印的 SQL 复制到数据库里执行,看是不是 SQL 语法错误、参数不匹配、表字段不存在的问题。
- 2. 接口返回数据错误排查:先看前端传入的参数是不是正确,再打断点调试,看参数从 Controller 层到 Service 层、Mapper 层的传递过程中有没有问题,再看 SQL 执行的结果是不是符合预期,一步步定位问题位置。
- 3. 接口响应慢排查:先看是不是 SQL 查询慢,用 explain 看执行计划,有没有全表扫描、索引失效,优化 SQL 和索引;再看是不是代码里有循环查询数据库、频繁创建对象的问题,优化代码逻辑,避免无效操作。
整理接口问题排查的通用决策流程图,覆盖 90% 的初级开发常见问题:
五、面试答题技巧与避坑指南
对于应届生和初级开发,很多时候不是知识点不会,而是答题方式不对,踩了面试的坑,导致拿不到 offer。我结合自己的面试经历,总结了 5 个最实用的技巧和避坑方法,完全适配初级岗位。
5.1 真诚答题是第一原则
这是阿里面试官最看重的一点,对于初级开发,不会不可怕,可怕的是不懂装懂、瞎编乱造。
- 面试时遇到不会的题,直接坦诚说 “这个知识点我目前还没有深入接触过,只了解一点基础概念,后续我会重点去学习”,绝对不要瞎编答案,面试官都是一线开发,你编的内容对不对,一听就知道,不懂装懂直接会被 pass。
- 项目经验不要夸大,自己没做过的内容不要说,面试官会针对你说的内容深挖,比如你说自己做了分布式锁,面试官一问底层原理、锁超时问题,你答不上来,直接就会被认为不诚实,反而不如老老实实说自己做的 CRUD 模块。
整理面试答题的正确与错误路径对比图:
5.2 避免死记硬背,用理解代替定义
很多应届生面试时,只会背书本上的定义,比如面试官问什么是多态,只会背 “同一行为具有不同表现形式”,面试官根本不会给高分,因为他不知道你到底懂不懂。
- 正确的做法是:先一句话说清楚核心概念,再结合自己的开发场景讲理解,比如 “多态就是同一个方法,不同的子类有不同的实现,调用时会根据实际的对象执行对应的方法,我在项目里做商品价格计算时,定义了一个价格计算的接口,普通商品和会员商品的实现类分别重写了计算方法,调用时用接口引用接收实现类对象,就能执行对应的价格逻辑,这就是我理解的多态”。
- 哪怕你说的定义不是百分百标准,只要能结合场景讲清楚自己的理解,面试官就会认为你真的懂了,而不是死记硬背。
整理高分答题与低分答题的逻辑对比流程图:
5.3 结合实例答题,提升说服力
初级开发面试的通病是,答题全是理论,没有实际的例子,面试官听了之后,不知道你会不会用这个知识点。
- 所有的知识点,都要结合自己的项目、课程设计里的例子来讲,比如问 String 和 StringBuilder 的区别,不要只说 “String 不可变,StringBuilder 可变,性能好”,要补充 “我在项目里做商品多条件查询时,需要动态拼接 SQL 的查询条件,用的就是 StringBuilder,因为拼接次数多,用 String 会创建大量临时对象,影响性能,这是我实际开发里的用法”。
- 有实例的回答,比干巴巴的理论有说服力 10 倍,也能让面试官知道,你不是只会学知识点,还能把知识点用到实际开发里,这正是初级开发岗位需要的能力。
整理面试答题的黄金结构流程图,初级开发可以直接套用:
5.4 主动暴露合理不足,展现学习潜力
对于应届生,阿里不会要求你什么都会,反而很看重你的学习能力和成长潜力,主动暴露合理的不足,比硬撑着说自己什么都会更加分。
- 面试时,我主动和面试官说 “我目前的开发经验都是基础的 CRUD 开发,对于高并发、分布式架构这些内容,只了解基础的概念,还没有实际的项目经验,后续我会跟着阿里的技术文档,一步步深入学习,提升自己的技术能力”。
- 这里的核心是 “合理的不足”,不能说自己 Java 基础不会、CRUD 开发不熟练,这是岗位的必备能力;要说那些对于初级开发来说,不会也很正常的内容,同时要说出自己后续的学习计划,展现自己的学习意愿和潜力,这正是阿里对应届生的核心要求。
整理面试中不足表述的正确与错误方式对比图:
5.5 高频延伸题提前准备
初级面试的知识点延伸性很强,很多题都是从基础知识点延伸出来的,提前准备好,就不会被问住,我总结了几个高频的延伸方向:
- 面向对象延伸:问接口和抽象类的区别、重写和重载的区别,提前结合场景准备好例子。
- String 延伸:问 String 为什么不可变、== 和 equals 的区别、String 的 intern () 方法,提前了解基础原理。
- 集合延伸:问 ArrayList 的扩容原理、HashMap 的底层实现、HashSet 和 HashMap 的区别,初级开发不用讲太深入的源码,讲清楚核心逻辑即可。
- 异常处理延伸:问 try-catch-finally 的执行顺序、throw 和 throws 的区别、自定义异常的用法,结合自己的项目准备例子。
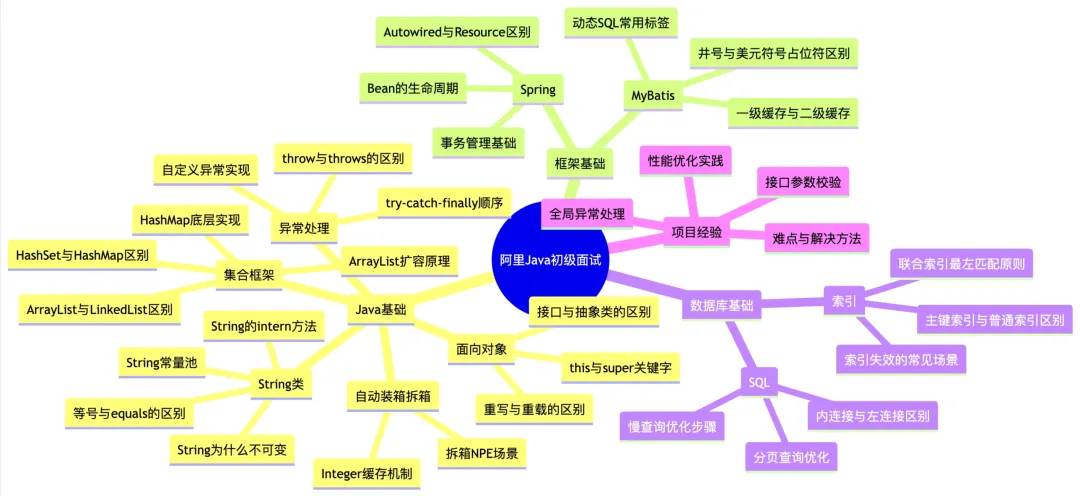
整理初级 Java 面试核心知识点的延伸考点思维导图,提前准备全覆盖:
最后想和和我一样刚起步的小伙伴说,阿里初级开发岗位,真的没有大家想的那么难,它不要求你有多么厉害的技术,核心就是看你基础扎不扎实、有没有开发思维、愿不愿意学习。不用贪多求深,把 Java 基础、框架基础、数据库基础打牢,把自己做过的项目理清楚,真诚答题,就已经超过了大部分候选人。希望我的这份复盘,能帮到大家,祝我们都能拿到心仪的 offer。