很多应届生准备简历的方式是这样的:
认真做一份,然后用它投几十个岗位。海投。用户运营投这份。产品经理也投这份。增长运营还是这份。
投出去,没有回音。
然后开始怀疑自己经历不够,开始问别人要简历模板,开始让 AI 帮忙"优化",加几个看起来很厉害的词,把"参与"改成"主导",把"协助"改成"负责"。
发出去,还是没有回音。
但问题从来不是经历不够,也不是遣词造句不对。是这份简历表达出来的"人设",和目标岗位根本不是一回事。
我做了一个 Skill,想解决这件事。
为什么想做这个
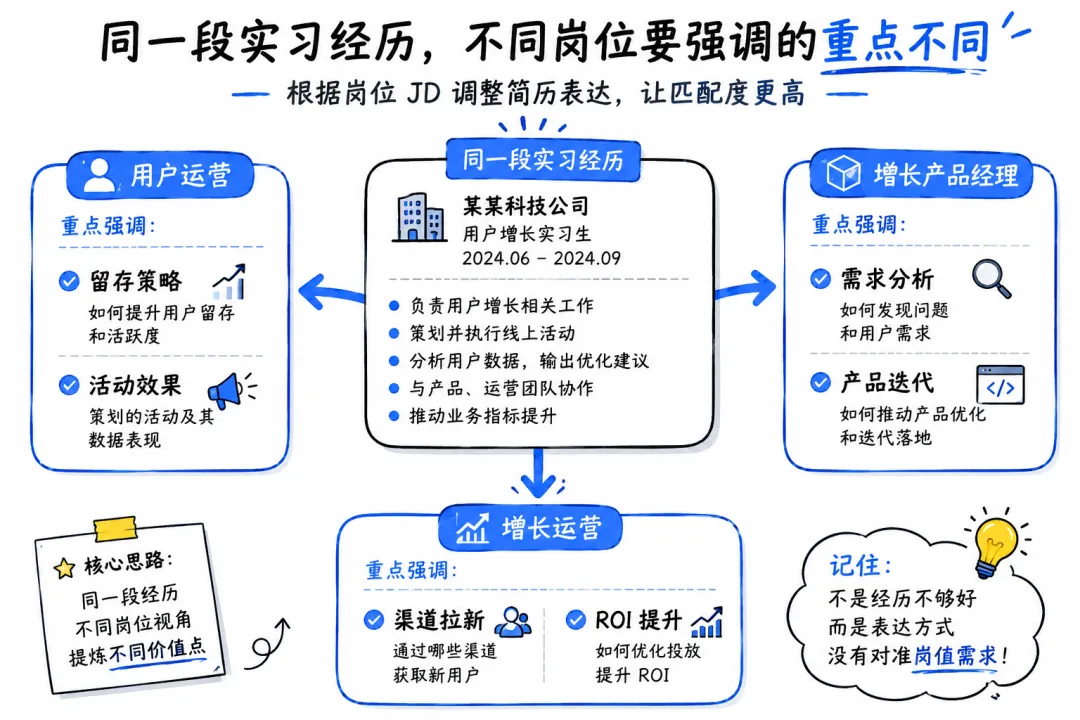
同一个候选人,同一段在某互联网公司做用户增长的实习经历——
投用户运营岗,应该强调用户分层、留存策略、运营活动效果。投增长产品经理岗,应该强调需求分析、产品迭代、跨团队协作。投增长运营岗,应该强调渠道拉新、ROI、增长数据。
同一段经历,三个岗位需要的表达方式完全不同。但大多数应届生用的是同一份简历。
不是因为他们不努力,是因为每次都针对 JD 改简历,真的很耗时间,而且不知道该改哪里。
所以我想做一个工具,帮求职者在投递之前先看清楚一件事:这份简历,真的在回应目标岗位吗?
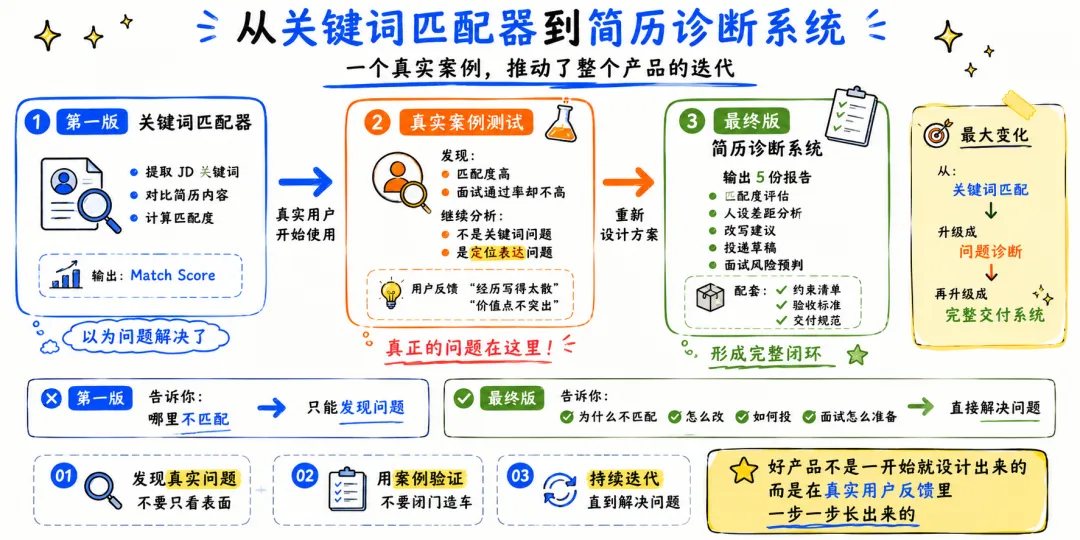
第一版:只是一个关键词匹配器
第一版我写得很快。功能是这样的:读取简历文本和 JD,提取关键词,计算覆盖率,标记"负责、参与、协助"这类弱表达,生成面试追问。
跑起来之后,看起来挺像那么回事。匹配度 72%,缺失关键词:数据分析、A/B 测试、用户分层。建议改写三处。
但我知道这版有问题:文件处理不稳定,PDF 提取经常错行;分数看起来精确,实际只是启发式规则;改写建议太模板化;最关键的——它只能告诉用户哪里不对,不能形成一份可以继续修改的简历草稿。
诊断出问题,但不给方向,用户还是不知道怎么改。
两份真实简历,暴露了什么
第一版跑通之后,我找来了两份真实的应届生简历,和两份真实的增长岗位 JD,做了测试。
问题一:关键词出现,不代表真的具备能力。
两份简历里都出现了"数据分析"。但一份是"参与数据分析工作",另一份是"独立搭建用户行为分析模型,识别高价值用户特征,支撑 DAU 提升 18%"。
关键词匹配器给两份简历的这个维度打了差不多的分。但招聘方看到的完全是两回事。
问题二:数据很多,不代表岗位匹配度高。
其中一份简历数据密度很高,每条经历都有数字。但这些数据全部集中在内容运营方向:阅读量、粉丝增长、转化率。而目标岗位是增长产品经理,需要的是产品迭代数据、需求排期经验、研发协作记录。
数据不少,但方向全错了。
问题三:"用户增长运营"和"增长产品经理"看起来像,人设其实不同。
用户增长运营的核心人设:执行力强,懂渠道,会做活动,能跑数据。增长产品经理的核心人设:懂需求,能跟研发对话,有产品 sense,能把业务问题翻译成产品方案。
这才是简历没有回音的真实原因。不是经历不够,是人设不对。
最关键的升级:加入岗位人设分析
意识到这个问题之后,我加了一个新的输出模块:positioning-report.md
它要回答的不是"关键词写没写",而是:招聘方看完这份简历,会把你归类成什么样的人?
具体分析四件事:当前简历呈现的候选人人设是什么。目标岗位期待的候选人人设是什么。两者已经重合的能力有哪些。还缺少哪些项目证据,简历经历应该如何重新排序。
举个例子,投增长产品经理岗位时,positioning-report 可能会输出:
当前简历人设:执行型运营,擅长活动策划和数据跑量。目标岗位人设:产品思维的增长 PM,能从业务问题出发提出产品解决方案。已重合能力:数据敏感度、用户分层意识。缺少证据:没有需求文档、没有研发协作经历、没有产品迭代案例。建议:把实习中参与的产品改版内容提到最前面,写清楚你的判断和贡献,而不只是执行结果。
从三份报告升级为五份报告
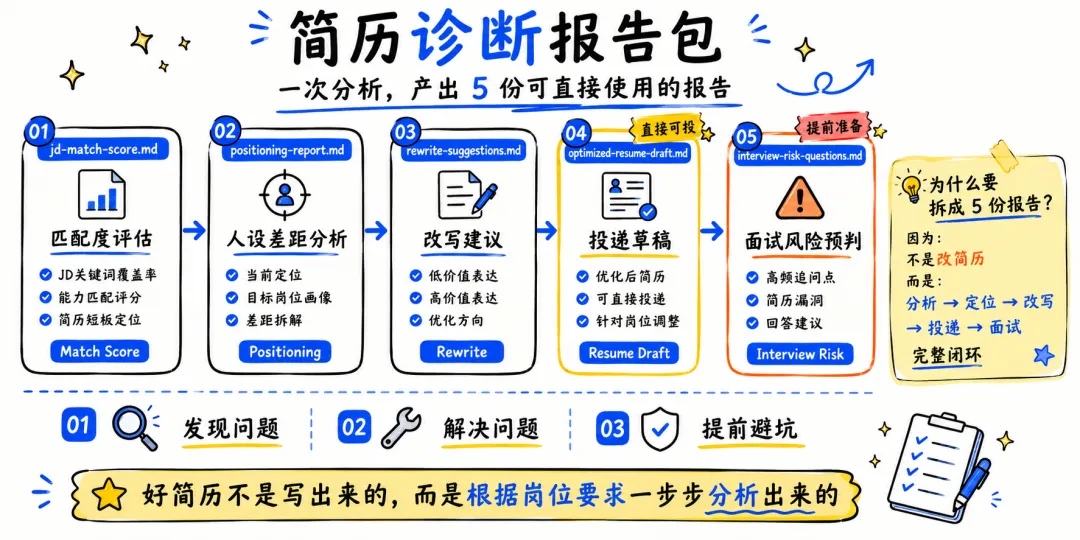
最终版输出五份报告:
jd-match-score.md —— 匹配度、关键词覆盖和结果证据。
positioning-report.md —— 当前人设 vs 目标人设差距。
rewrite-suggestions.md —— 标出弱 bullet,结合 JD 给具体改写方向。
optimized-resume-draft.md —— 生成一版投递草稿,信息不足处用【占位符】标注,需要候选人确认。
interview-risk-questions.md —— 提前准备面试被追问的高风险问题。
如何防止 AI 乱编简历
AI 改简历最大的风险不是改得不好,是改得"太好了"。
这个 Skill 的约束写得很明确:
不编造公司名称和项目经历。不编造实习职责和工作内容。不编造数据、奖项和技术栈。不把团队成果改写成个人贡献。信息不足时用【占位符】,不自行填写。所有改写必须由求职者确认后才能使用。不承诺通过 ATS 或拿到面试。
简历工具的价值应该是放大真实经历,而不是制造虚假经历。
技术实现,简单说
用 Python 写的。支持 TXT、Markdown、DOCX 格式直接输入。安装 pypdf 之后支持文本型 PDF。扫描版 PDF 还不支持,需要 OCR。
可以安装到 Codex、Claude Code 等 Agent,直接调用。已发布到 GitHub 开源,项目名:resume-jd-matcher。
这次开发给我的几个判断
不要一开始追求大而全。第一版只做了关键词匹配,功能很简单,但正是因为简单,才能快速测试,发现真实问题。
真实案例比继续优化 Prompt 更重要。拿到两份真实简历之前,我以为问题是 Prompt 写得不够好。拿到之后才发现,根本问题是产品逻辑——关键词匹配根本回答不了"这个人适不适合这个岗位"。这不是改 Prompt 能解决的。
"不做什么"是 AI 产品很重要的能力。 边界越清楚,工具越可信。
Skill 的价值来自稳定工作流,不只是一个长 Prompt。第一版是一个 Prompt,现在的版本是五份报告、一套处理规则、一份约束清单、一个可以重复调用的流程。用一次和用一百次,结果应该是稳定的。这才是 Skill。
结尾
这个工具不能替应届生变出三段顶级实习经历。也不能保证投出去就有面试,有面试就能拿 offer。
但它可以帮你在投递之前回答一个问题:
这份简历,真的在回应目标岗位吗?
如果答案是"不确定",至少值得花十分钟跑一遍,看看输出报告里有没有你之前没意识到的东西。
你在投简历时,会针对不同 JD 专门修改简历吗?
如果想体验这个开源 Skill,评论区回复「简历」,我发给你。