大家好,我是大志。
在这个Agent AI 面试题系列文章中,我系统整理了一套AI Agent 面试题体系,帮助你从零搞懂 Agent 的核心概念、RAG、记忆、LangChain与LangGraph用法以及工程实践相关的面试题,带你轻松应对面试。
说实话,网上一堆讲Agent面试题,但是能讲明白的真不多,我把自己整理的面试题和答案分享给大家,全程人话,非常容易理解。准备面试的朋友,闭眼抄作业就可以了。
除此之外,大家也可以在线阅读完整面试题文档:aiflowline.cn
1、什么是 AI Agent?
AI Agent 是一种以目标为驱动,利用大语言模型(LLM)进行推理和决策,通过调用工具(Tool)与外部环境交互,并结合记忆(Memory),进行逻辑循环,直到完成任务的智能系统。
在 LangChain 的官网将Agent定义为:Agent=Model + Harness
其中Model就是指LLM大语言模型,Harness可以理解为让LLM真正能干活的一套运行框架,包含工具调用、记忆管理等功能,单纯使用Prompt+Model只具备推理能力,而LLM+Harness才是一个真正又能思考、又能行动的AI Agent智能体。
2、Agent 和普通聊天机器人的区别是什么?
AI Agent与传统 ChatBot 最大的区别在于:
一个AI Agent的执行流程如下:
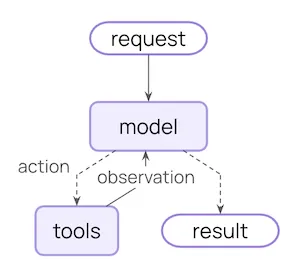 Core agent loop diagram
Core agent loop diagram例如用户要求:"帮我整理最近一周AI Agent领域的重要新闻并发送到邮箱“,ChatBot只能告诉用户怎么做,而Agent可以自主完成:
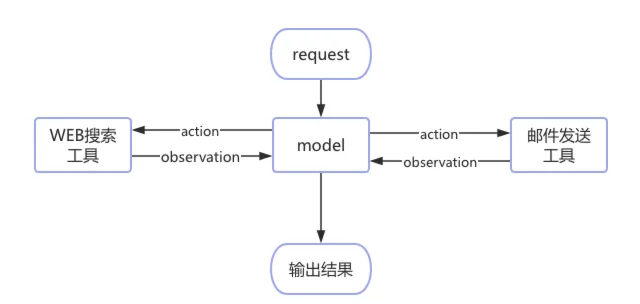 image-20260604103121798
image-202606041031217983、Agent 的核心模块有哪些?
一个完整的 AI Agent 通常由以下五个部分组成:
(1)大语言模型(LLM)
Agent 的"大脑",负责理解用户意图、进行推理、做出决策。LLM 的能力上限基本决定了 Agent 的能力上限。
(2)工具(Tools)
工具是 Agent 的"手脚",LLM 本身只能生成文本内容,但通过工具可以与外部世界交互,比如:联网搜索、代码执行器、API调用、文件读写等。
(3)记忆(Memory)
LLM作为Agent的大脑,它本身不具备记忆能力,在和Agent对话的过程中,需要把过往的历史记忆信息一并传递给LLM,才能让Agent拥有记忆。
目前,Agent 的记忆系统分为两种:
- 短期记忆:当前对话的上下文,比如和LLM对话最近的十条消息。
- 长期记忆:持久化存储的信息,比如用户偏好,对话主题,长期记忆可以通过LLM对短期记忆进行总结,每次生成新的长期记忆。
(4)规划能力(Planning)
当 Agent 在面对复杂任务时,Agent 要把一个大目标拆解成多个小步骤,按计划逐步完成。
例如:
帮我做一个xxx竞品分析
Agent会制定计划:
1. 搜集竞品
2. 分析功能
3. 分析价格
4. 生成报告
(5)推理能力(Reasoning)
推理能力决定下一步Agent应该做什么,比如是否调用、调用哪个工具。
4、什么是 ReAct?
ReAct(Reason + Act)是一种 Agent 执行范式,通过“推理(Thought)→ 行动(Action)→ 观察(Observation)”的循环,让大模型能够自主决定何时调用工具、如何调用工具,以及如何利用工具结果继续推理,最终完成复杂任务。它是当前大多数 Agent 框架的基础思想之一。
Thought(推理) → Action(行动) → Observation(观察) → Thought(推理) → Action(行动) → Observation(观察) → ... → Final Answer(输出最终结果)
5、举例说明ReAct 的执行流程是什么?
假设用户问:"杭州今天的天气怎么样?"
Thought: 用户想知道杭州今天的天气,我需要调用天气查询工具
Action: 调用天气API,生成参数:城市=杭州,日期=今天
Observation: 杭州今天晴,气温 22-30°C,湿度 65%
Thought: 我已经拿到了天气数据,可以直接回答用户了
Action: 不需要再调用工具
Final Answer: 杭州今天天气晴朗,气温22到30度,湿度65%,比较适合出行。
整个过程中,LLM 先推理出需要做什么,再选择工具执行,拿到结果后,再继续推理,判断不需要调用工具后,直接给出最终答案。
6、ReAct 有哪些缺点?
ReAct 虽然简单直观,但在实际使用中会遇到几个问题:
(1)容易死循环
LLM 可能在 Thought → Action → Observation 之间反复循环,始终无法输出最终结果,消耗大量 token,可以限制循环次数来避免死循环。
(2)长任务容易丢失上下文
对于复杂任务,ReAct 会不断把 Thought → Action → Observation追加到上下文中,会造成token消耗增加、处理速度下降、模型注意力分散等问题。
(3)缺少全局规划
这是ReAct最核心的缺陷之一,ReAct 本质上是"走一步看一步",边想边做,没有全局的计划。在处理一些多步骤的复杂任务时,容易执行混乱或者遗漏步骤。
(4)token 消耗大
ReAct每执行一步都要让LLM思考一次,调用LLM的次数就会成倍增加,会造成大量token的消耗。
(5)执行速度慢
因为ReAct整个循环是串行执行,等到上一次工具调用结果返回,才能再次思考和调用工具,执行速度就会显得很慢。
(6)工具的选择不稳定
由于工具的选择是交给LLM的,因此工具的选择就具有不确定性,可能同一个问题每次调用的工具都不相同,比如这次用Google搜索工具,下次可能用Baidu搜索工具。
7、什么是 Plan-and-Execute?
Plan-and-Execute 是在 ReAct 基础上发展出来的一种 Agent 设计模式,它的核心思想是:先制定完整计划,再按计划执行。
Plan-and-Execute整个流程分为两个阶段:
(1)规划阶段:LLM 先把用户的任务拆解成一个有序的计划列表,比如:
任务:帮我分析竞品并生成报告
计划:
1. 搜索竞品A的公开信息
2. 搜索竞品B的公开信息
3. 对比分析两者的优劣势
4. 生成分析报告
5. 发送邮件
(2)执行阶段:按照计划列表,依次执行每一步。每完成一步,可以选择是否需要调整后续计划。
8、Plan-and-Execute 和 ReAct 的区别?
通过开车这件事来比喻 Plan-and-Execute 和 ReAct 的区别:
ReAct:每开10m,停下来继续规划路线,效率低下。
Plan-and-Execute:在出发前,先用导航规划好起点到终点的路线,再出发,效率更高。
以下是在各个维度对比 ReAct 和 Plan-and-Execute 的差异:
实际开发中,两种方式经常会结合使用:用 Plan-and-Execute 做全局规划,每一步执行时用 ReAct 来处理细节。
9、什么是 Reflection Agent?
Reflection Agent(反思型 Agent)是指Agent在完成任务后,不会直接把结果丢给用户,而是进行自我检查和改进,输出反思、优化后的结果。
整个过程可以理解为:
任务执行 → 回顾/检查 → 自我修正 → 再执行/优化 → 输出
Reflection 通常和 Plan-and-Execute、ReAct 结合使用:Plan-and-Execute 负责全局规划,ReAct 负责执行细节,而 Reflection 进行结果反思并进行优化。
10、Reflection 解决什么问题?
Reflection 主要解决 Agent 一次性生成结果质量不稳定、执行过程中无法自我纠错的问题。
在实际生产中,Agent很容易出现以下问题:
(1) 工具使用错误:调用工具错误或者调用顺序错误。
(2) 输出结果不符合要求。
(3) 复杂问题遗漏步骤。
Reflection 通过”执行→检查→修正”的闭环机制,能有效提高复杂任务的输出质量。
总结一下,以上三种Agent设计模式:ReAct 解决“怎么做”,Plan-and-Execute 解决“做什么”,Reflection 解决“做得对不对”。
11、什么情况下用单Agent?
当满足以下场景,更加适合使用单 Agent:
(1)任务目标明确
用户的需求很明确,不需要多个领域协作。比如:天气预报查询、知识库问答、代码生成等场景。
(2)任务链路较短
任务的执行流程比较简单,基本就是一条直线走下去,不需要太多的分支判断。
(3)工具数量不多
用到的工具数量不多,LLM很容易判断应该在什么时候调用什么工具,以及如何调用。
(4)角色单一
不需要明显的角色分工,比如产品经理、程序员、测试工程师等等。
12、什么情况下用多Agent?
以下场景适合用多 Agent:
(1)需要角色分工
比如让一个 Agent 负责搜集资料,另一个 Agent 负责撰写文案,第三个 Agent 负责审核校对。就像一个团队,每个人有明确的分工。
(2)任务之间有并行关系
有些子任务可以同时进行,多Agent 可以并行执行,提高效率。
(3)上下文过大
比如在分析一个大型项目源代码时,一个Agent的上下文明显不够,就按模块拆分,让不同的Agent去分析不同的模块。
(4)不同模型擅长执行不同任务
比如 GPT 擅长推理,Claude 擅长写代码,Gemini 擅长图片生成,就可以使用多Agent让不同Agent负责不同的模块。
13、多Agent一定比单Agent好吗?
不一定。 多 Agent 引入了更多的复杂性,很多情况下反而不如单 Agent:
Multi-Agent 的优势在于角色分工、并行处理和复杂任务协作,但同时会带来以下问题:
(1)更高的成本:多Agent调用LLM次数增加,进而增加成本。
(2)更长的延迟:每个Agent进行推理、结果生成、传递信息,系统响应明显变慢。
(3)更复杂的调试:当出现问题时,排查是哪个Agent出现问题会很困难。
(4)Agent 间通信损耗:Agent之间靠文本传递信息,可能会丢细节。
在实际项目中,通常遵循“先单 Agent,后 Multi-Agent”的原则:当单 Agent 能够完成任务时优先保持简单,只有在任务复杂度、上下文规模或协作需求达到一定程度时,才引入 Multi-Agent 架构。
14、Agent 和 Workflow 的区别是什么?
Workflow 是由开发者预先定义好的执行流程,步骤和路径基本固定;而 Agent 则依赖LLM进行动态决策,根据当前状态自主选择下一步行动。
Workflow 具有稳定、可控、易调试的特点,适合规则明确的业务流程;
Agent 具有灵活、自主和适应复杂任务的优势,但成本和不确定性更高。
在实际项目中,通常会将 Workflow 和 Agent 结合使用,用 Workflow 管理整体流程,用 Agent 处理需要LLM决策的环节。
15、哪些业务场景根本不适合 Agent?
Agent 虽然强大,但并不是所有场景都适合用:
(1)对准确性要求极高
比如金融交易、医疗诊断这类领域,LLM 有可能出现幻觉或做出错误判断,一旦出错后果严重。
(2)简单的 CRUD 操作
如果业务逻辑就是增删改查,完全不需要 Agent。用传统的 Web 框架就能搞定,引入 Agent 只会增加复杂度和成本。
(3)实时性要求高
Agent 每做一步决策都要调用 LLM,响应时间通常在几十秒甚至更长时间。如果业务要求实时性很高,Agent 不适合这种场景。
(4)流程固定
在任务执行时,每一步做什么、怎么处理都已经很明确了,用 Workflow 比用 Agent 更合适、更可控。
(5)数据敏感性强
Agent 在执行过程中可能会把敏感数据传输给 LLM,如果对数据安全有严格要求,不适合使用开放的大模型,可以自行本地部署大语言模型,这样可以保证数据不外流。
好啦,今天这期Agent基础面试题就到这里。后面我会每周至少更新1期面试题系列,想看后续 【AI Agent进阶面试题】 的朋友,欢迎关注「大志说编程」!
觉得有用的话,转发给正在面试的小伙伴,咱们下期见~
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
