大家好,我是小米,前几天,一位准备跳槽的朋友跑来找我,他说:“小米,我最近在准备Java社招面试,面试官问了我一个问题:Dubbo服务降级、失败重试怎么做?我当时只知道重试次数配置,结果被面试官追着问了十几分钟,最后直接懵了。”
我听完笑了,这个问题看起来简单,实际上背后涉及分布式系统稳定性设计思想,今天我们就通过一个故事,把Dubbo服务降级和失败重试彻底讲明白。
假设你开了一家大型餐饮集团,集团里面有很多部门:
某天中午12点,大量用户开始下单,系统瞬间涌入几十万请求,此时有个用户下单流程如下:
本来一切正常,突然支付服务出现问题,服务器CPU飙升,响应时间从20ms变成了20秒,这时候如果订单服务还傻乎乎等待支付服务返回结果,那么大量线程都会被卡死,最终整个系统全部崩溃,这就是分布式系统最经典的问题:雪崩效应。
于是Dubbo引入了很多保护机制,其中最重要的两个:
服务降级(Fallback)本质上就是核心功能保住,非核心功能先放弃,就像餐厅突然爆满,老板会怎么做?
正常情况:
高峰期:
牺牲部分体验,保证整体服务可用,这就是降级。
假设订单服务调用用户积分服务,正常逻辑:
UserPoint point = pointService.query(userId);
结果积分服务挂了,如果不处理:
怎么办?直接返回默认值 return new UserPoint(0);,即:
虽然积分展示不准确,但订单还能下,用户还能买东西,系统还能活着,这就是降级。
Dubbo主要通过Mock机制实现,配置方式:
或者
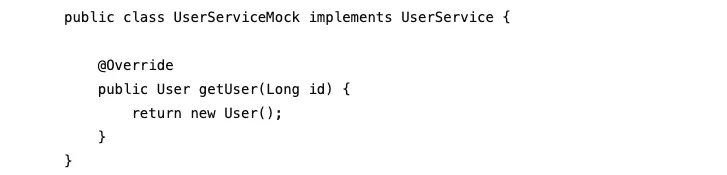
然后编写Mock实现类:
调用流程:
用户几乎感觉不到服务故障。
面试经常问,不要只回答Mock,要说出降级思想。
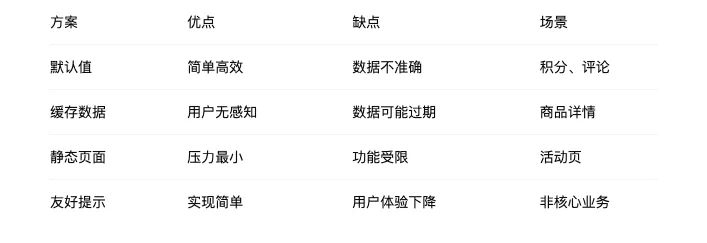
1 返回默认值
最常见,例如:
2 返回缓存数据
例如商品详情页,数据库挂了,直接返回Redis缓存。
用户仍然可以浏览商品。
3 返回兜底页面
电商大促常见,系统繁忙 请稍后再试,虽然体验不好,但总比系统崩溃强。
4 常见降级策略对比
再回到餐厅故事,服务员去厨房催菜,第一次没人回应,怎么办?
Dubbo默认就支持失败重试,调用流程:
目的是解决:
等问题。
很多面试官喜欢问,默认配置:retries=2。
注意很多人误解了,Dubbo默认不是调用2次,而是第一次调用 + 重试2次,总共3次调用,流程:
1、XML方式:
<dubbo:reference retries="3"/>
2、注解方式:
3、YAML方式:
这里是面试高频陷阱,很多人以为重试越多越好,错!有些业务绝对不能重试。例如:
1、支付
扣款100元,第一次其实成功了,但网络超时,Consumer认为失败,再次重试,结果:
用户直接炸锅。
2、创建订单
创建订单,重试后:
出现重复订单。
3、发短信
验证码发送,重试后收到3条验证码,用户体验极差。
4、不建议重试的业务
对于幂等性差的接口,建议直接关闭:
@DubboReference( retries = 0 )
或者:
<dubbo:reference retries="0"/>
此时:
不会再次调用。
如果面试官问:“Dubbo服务降级、失败重试怎么做?”
不要只回答配置项,优秀回答应该这样说:
Dubbo为了提升分布式系统可用性,提供了服务降级和失败重试机制。服务降级通常通过Mock实现,当Provider异常或不可用时返回默认值、缓存数据或兜底结果,从而避免故障扩散。失败重试主要用于解决网络抖动和瞬时故障,Dubbo默认retries=2,即总共调用3次。但对于支付、下单、发短信等非幂等接口应关闭重试,否则可能导致数据重复。实际生产环境中通常会结合超时控制、线程隔离、限流熔断以及降级策略共同保障系统稳定性。
当你能把:
服务降级
Mock机制
默认重试次数
幂等性问题
重试风险
生产实践
全部串起来回答的时候,面试官基本就知道你做过真实的分布式系统,而不仅仅是背过八股文。
因为真正优秀的系统,从来不是“永不失败”,而是在失败来临的时候,依然能够优雅地活下去。
好朋友们,我们下篇见~