我(小张),211本科计算机相关专业,有8个月Java开发实习经验,校招投递阿里淘宝业务线Java P5开发岗,最终顺利拿下offer。这篇复盘完整还原了大模型应用开发方向的全流程面试,针对校招/1年以内经验的初级岗定位,拆解每一道题的应答逻辑、心理博弈和避坑指南,帮大家真正做到“手里有活、心里不慌”。
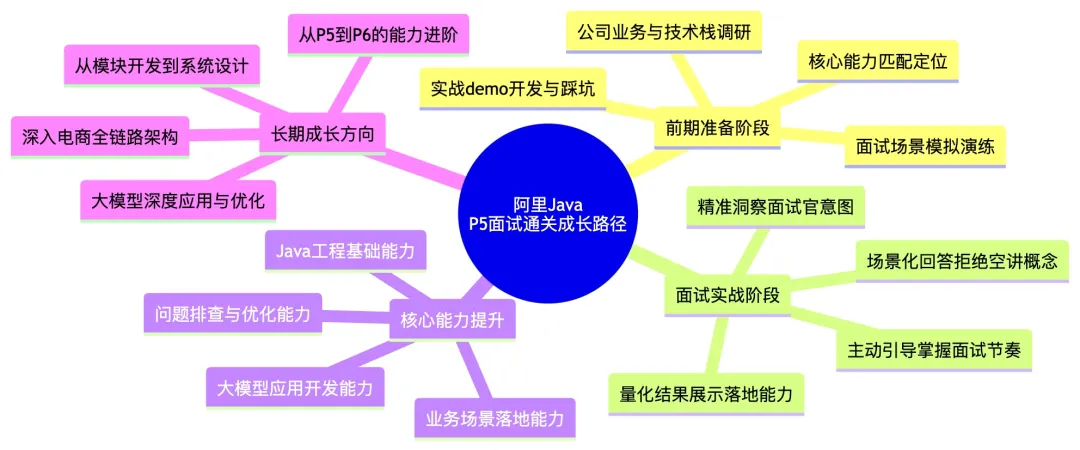
1. 战前部署:知己知彼(面试前准备)
公司画像拆解
阿里淘宝/天猫作为国内头部电商平台,大模型的落地逻辑非常明确——所有能力都围绕「商家降本提效、用户体验优化」两个核心方向。商家端的商品文案生成、标题优化、评价分析,用户端的智能客服、售后工单处理、购物导购,都是和Java开发强相关的落地场景。
技术栈上,阿里内部核心以Java生态为主,Spring Boot/Spring Cloud Alibaba是标准开发框架,大模型优先使用自研通义千问,配套Sentinel限流、Nacos配置中心、Arthas问题排查等开源组件,完全是阿里系的技术闭环。文化上,P5级别的核心要求是基础能力达标、能上手干活、有成长潜力,不需要你是算法大牛,但必须务实、有结果意识,能配合团队完成AI功能模块开发。
定制化备战策略
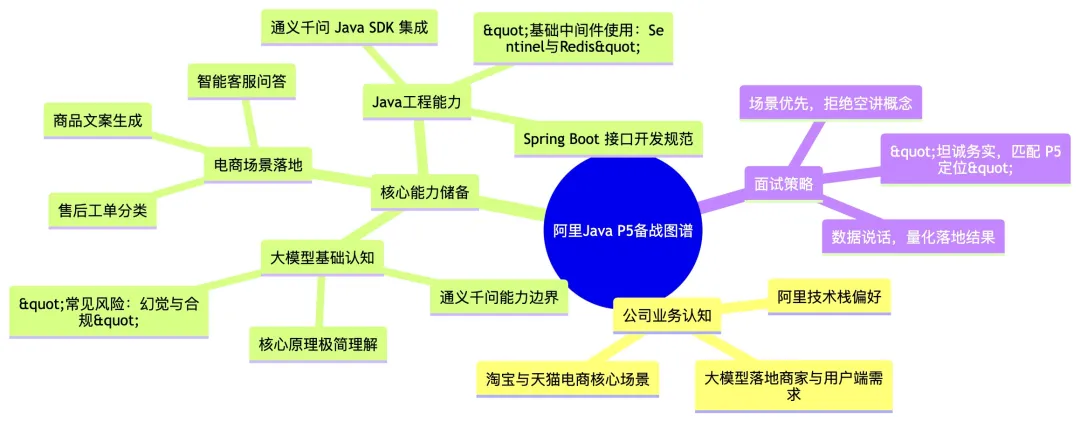
针对P5的岗位定位,我没有死磕大模型底层算法(比如Transformer反向传播、注意力机制数学推导),而是精准聚焦3个核心备战方向,完全贴合岗位要求:
1. 大模型基础认知:重点搞懂「能做什么、不能做什么」,尤其是通义千问的能力边界、token限制、幻觉问题等开发必踩的风险点,而非背概念;
2. 工程能力落地:提前用Spring Boot 2.7.x集成通义千问官方Java SDK,跑通了商品文案生成、文本分类的完整demo,写了符合开发规范的接口,包括参数校验、异常处理、重试熔断,甚至做了本地压测,把踩坑细节全部记了下来;
3. 业务场景绑定:把所有技术点都和淘宝/天猫电商场景做了映射,比如文本生成对应商品详情页开发,语义分类对应售后工单处理,确保每一个回答都能落地到真实业务,而非纸上谈兵。
心态建设
校招面试最忌两个极端:要么过度紧张大脑空白,要么盲目自大瞎吹牛皮。我的调整策略很简单:把面试官当成未来的同事,而非考官,面试的核心是展示「我能快速上手团队的活,不给团队添麻烦,还能落地结果」,而非证明「我什么都懂」。
提前给自己定了两条铁律:不会的内容坦诚说明,同时讲清楚自己的学习思路,绝对不瞎编;会的内容,一定结合业务场景讲落地细节,绝不空背概念。
【配图】备战知识图谱
2. 实战演练:见招拆招(面试核心过程)
这部分是面试的核心,我选取了4道围绕主题的必考题,完整还原每道题的意图洞察、踩坑陷阱、高分应答逻辑,全程都是第一视角的真实面试场景。
问题1:你对大模型的基本原理,以及通义千问这类主流大模型的能力边界和局限性,有什么理解?
- 🎯 意图洞察
`【内心OS】`:一上来就问这个,绝对不是要考我Transformer的源码推导,毕竟是P5校招岗,不是算法岗。他真正想判断的,是我有没有清醒的认知,会不会在开发里瞎用大模型。很多应届生要么上来背一堆公式,要么把大模型吹成无所不能,这都是线上踩坑的前兆。他要的关键词是:基础认知清晰、知道能力边界、有风险意识、能结合业务。
- 🚫 普通人的陷阱
大多数候选人会踩两个极端:要么死背概念,从Transformer讲到自注意力机制,堆一堆专业术语,完全没说和开发有什么关系;要么张口就来“大模型能写代码、能生成文案、能做推荐,什么都能做”,完全不提局限性。前者会让面试官觉得你只会背书,不会落地;后者会让面试官觉得你对大模型没有敬畏心,上线后大概率会踩合规、幻觉的大坑,两个回答都拿不到高分。
- ✅ 我的破局思路(高分回答)
我没有上来就讲原理,而是先给了一个极简的核心认知,再结合电商场景讲能力,最后重点讲边界和局限性,全程贴合开发的实际需求。
我是这么说的:
“首先我对大模型核心原理的理解,本质上它是一个基于海量文本数据训练出来的、能根据上文预测下一个token的概率生成模型,核心是通过学习文本的语义和逻辑,生成连贯、符合人类意图的内容。对于我们Java开发来说,不需要深入到算法训练的细节,核心是理解它的生成逻辑,才能用好它的API,规避线上风险。
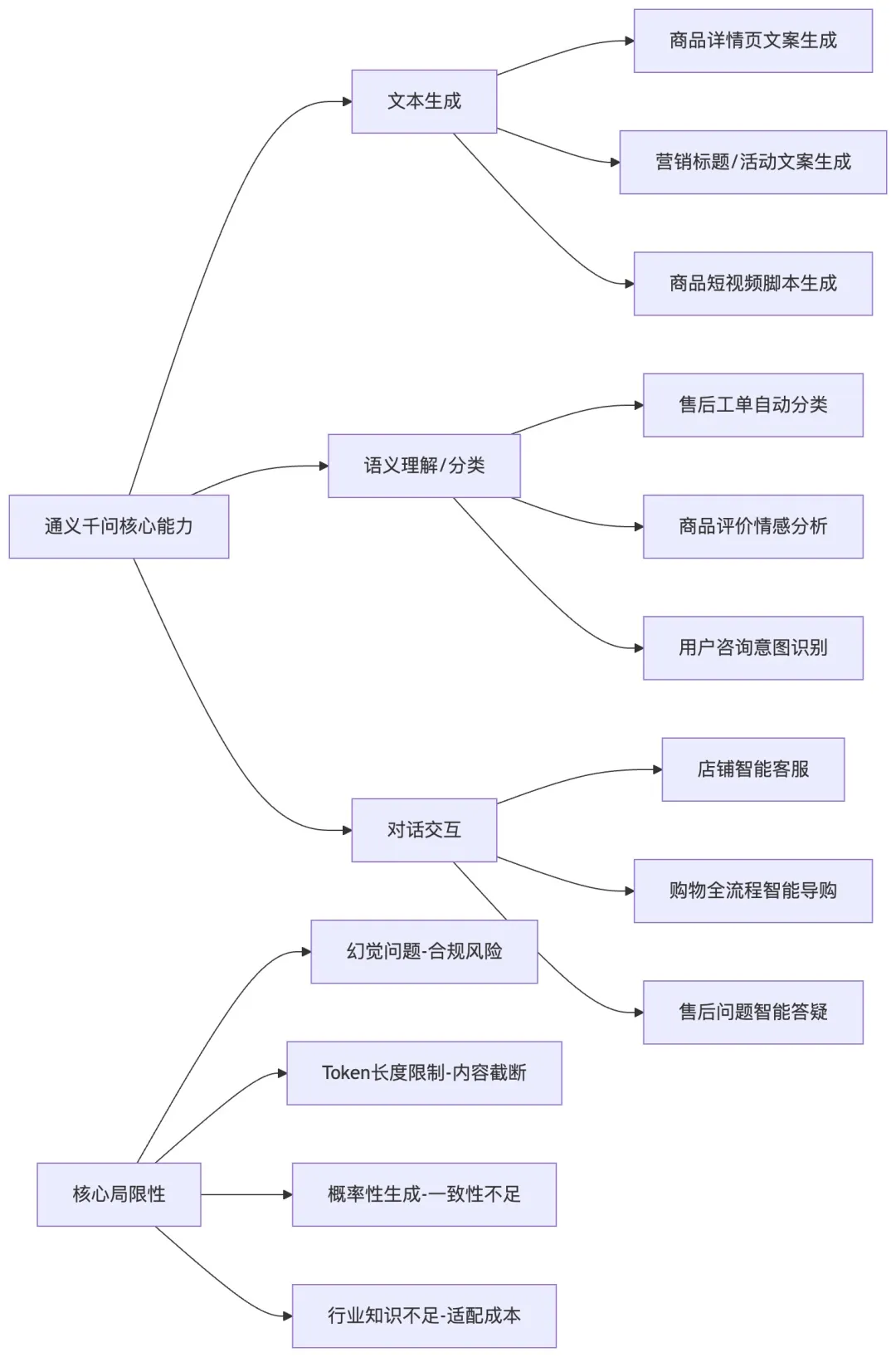
然后是通义千问这类大模型的核心能力,结合淘宝/天猫的电商场景,我觉得最常用、和开发强相关的有3类:第一是文本生成能力,比如商家的商品详情页文案、营销标题、短视频脚本生成;第二是理解和分类能力,比如用户的售后工单分类、商品评价的情感分析、用户咨询的意图识别;第三是对话交互能力,比如店铺的智能客服、用户购物过程中的智能导购问答。
但更重要的是它的能力边界和局限性,这也是我们做开发的时候必须重点关注的,我总结了4个和电商业务落地强相关的核心点:
第一是幻觉问题,大模型会生成看起来很合理、但不符合事实的内容,比如在商品文案里生成虚假的产品参数、不符合广告法的绝对化用语,这在电商场景里是致命的,会给商家带来合规风险;
第二是token长度限制,通义千问不同的模型有固定的上下文窗口限制,比如常用的通义千问7B模型,上下文窗口是8k,要是商家传入的商品参数、历史文案太长,超出了窗口,就会出现内容截断、生成逻辑混乱的问题;
第三是实时性和确定性不足,大模型的生成是概率性的,同一个prompt,两次调用生成的内容可能不一样,而且API调用的RT波动比较大,高峰期可能会有几百ms的延迟,不适合用在对实时性、一致性要求极高的交易链路里;
第四是行业知识的局限性,通用大模型对淘宝/天猫的平台规则、电商行业的专业知识理解不够深,比如平台的广告法规范、商品发布规则,直接用通用模型生成的内容,很可能不符合平台要求,需要通过prompt工程或者知识库来优化。”
说完之后,我主动补了一句:“这些局限性,我在自己做商品文案生成的demo的时候,都实际遇到过,也做了对应的兜底方案,比如在prompt里严格约束不能用绝对化用语,生成后做关键词合规校验。” 面试官当时点了点头,顺着这个话题就问了下一个核心问题。
【配图】大模型能力与电商场景映射图
问题2:如果让你基于Java Spring Boot生态,通过通义千问官方SDK,实现一个商品文案生成的接口,你会怎么做?
- 🎯 意图洞察
`【内心OS】`:来了,这是核心题,完全贴合P5的岗位要求,就是看我能不能真的动手干活,不是纸上谈兵。面试官要的不是“我会调用SDK”,而是看我有没有基础的工程素养,能不能把一个接口做稳、做规范,符合阿里的开发标准。他要的关键词是:规范的接口设计、完整的异常处理、业务场景适配、基础的工程化保障。
- 🚫 普通人的陷阱
90%的应届生都会这么答:“首先引入通义千问的SDK,然后写一个Controller,接收前端的参数,调用SDK的API,把生成的结果返回给前端。” 这个回答只能算及格,绝对拿不到High Pass。因为它只完成了最基础的功能,完全没考虑工程化的东西,比如参数校验、异常处理、超时重试、幂等性、合规校验,这些都是线上开发必须要考虑的,面试官要招的是能上线写代码的人,不是只会写demo的学生。
- ✅ 我的破局思路(高分回答)
我先给了一个明确的业务场景定位——淘宝商家后台的商品文案生成功能,商家输入商品的标题、核心卖点、规格参数,接口生成符合淘宝平台规范的商品详情页文案,然后分步骤讲了完整的实现方案,全程结合自己实际写demo的踩坑经历。
我是这么说的:
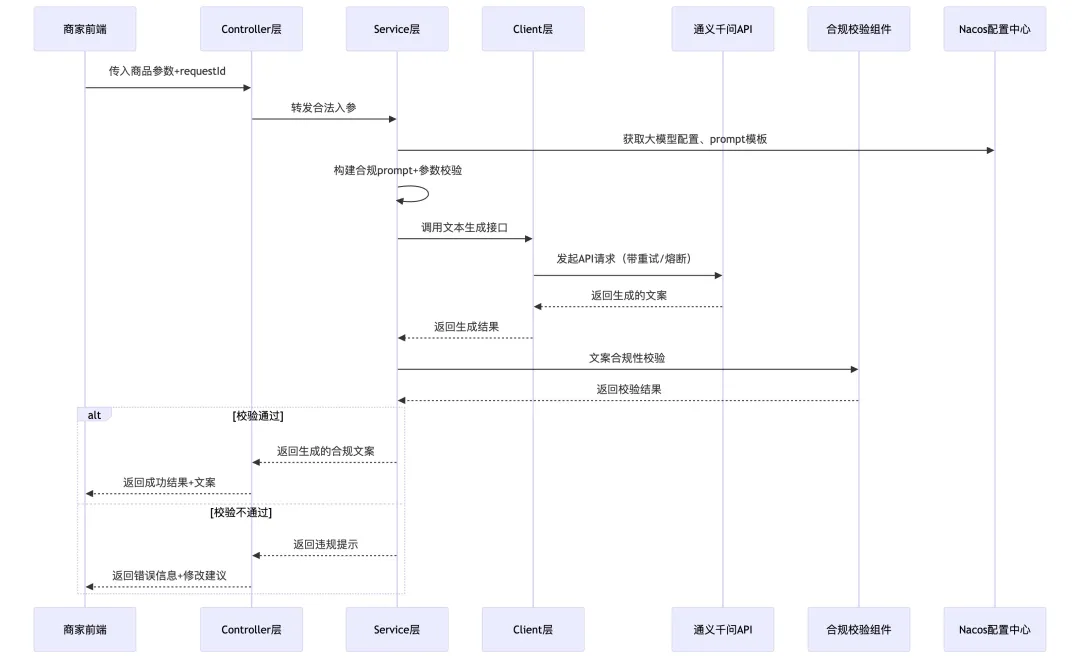
“这个需求,我之前自己用Spring Boot 2.7.x + 通义千问Java SDK 2.x版本实际实现过,完整的流程分为6个核心步骤,从接口设计到上线兜底都覆盖了:
第一步,项目搭建与依赖集成,首先创建标准的Spring Boot项目,引入通义千问的官方Java SDK,同时引入Spring Cloud Alibaba的基础组件,比如Nacos做配置管理,把通义千问的API Key、模型名称、超时时间这些配置放到配置中心,避免硬编码;Sentinel做基础的限流,还有Spring Validation做参数校验,这些都是阿里系的标准技术栈,上手就能用。
第二步,接口规范与参数设计,按照阿里的Java开发规范,设计RESTful风格的POST接口,路径是`/api/v1/ai/goods-copy`,入参用DTO封装,必填字段包括商品标题、核心卖点、商品类目,选填字段包括规格参数、文案长度要求、风格要求,同时加上requestId做链路追踪,方便排查问题。出参用统一的Result封装,包括生成的文案内容、requestId、状态码、错误信息,符合团队的统一返回规范。
第三步,核心业务逻辑实现,严格按照分层架构拆分:Controller层只做参数接收和结果返回,不写业务逻辑;Service层写核心逻辑,首先做参数的合法性校验,比如商品标题不能为空,类目必须是淘宝的合规类目,然后根据入参构建符合电商场景的prompt,严格约束“不能使用‘国家级’‘最高级’等广告法禁用的词汇,必须基于传入的商品参数生成,不能虚构卖点”,然后调用通义千问的生成接口;Client层单独封装通义千问的SDK调用,做统一的签名、超时设置,和业务逻辑完全解耦。
第四步,异常处理与兜底保障,这是线上接口最关键的部分,我当时踩过坑,第一次写demo的时候没做异常处理,高峰期API调用超时,直接把异常抛给了前端,体验非常差。所以我做了这几个处理:首先用全局异常处理器,捕获所有的业务异常和系统异常,统一返回友好的错误信息,不会把堆栈信息抛给前端;然后用Resilience4j做重试和熔断,针对API超时、服务不可用的情况,设置3次指数退避重试,重试间隔500ms,如果连续10次调用失败,就触发熔断,直接返回兜底文案,避免接口雪崩;还有幂等性处理,基于requestId做幂等,同一个requestId不会重复调用大模型API,避免商家重复点击导致的token浪费。
第五步,合规校验与风险控制,针对电商场景的合规要求,在大模型生成文案之后,加一层后置校验,用关键词匹配的方式,检查有没有广告法禁用的绝对化用语、虚假宣传的内容,如果有违规内容,直接拦截,返回给商家修改提示,避免合规风险。
第六步,基础的监控与日志,在接口的入口、SDK调用的前后、异常捕获的地方,都加上info和error级别的日志,打印requestId、入参、调用耗时、返回结果,方便排查问题;同时通过Micrometer埋点,监控接口的QPS、RT、成功率、token消耗量,这些都是线上必须的监控指标。
我自己本地用JMeter压测过,这个接口单实例在100QPS的压力下,平均RT控制在250ms以内,接口成功率99.9%以上,完全能满足商家后台的使用需求。”
说完之后,面试官问了我一句:“你为什么要把SDK调用封装到单独的Client层?” 我答:“第一是和业务逻辑解耦,后续如果要更换大模型,只需要修改Client层的代码,业务层完全不用动;第二是统一处理SDK的签名、超时、重试,避免在业务代码里重复写冗余的逻辑,符合单一职责原则。” 面试官当时笑了笑,说“对,这就是我们开发里的规范”。
【配图】商品文案生成接口时序图
问题3:你了解大模型在淘宝/天猫电商场景里,有哪些基础的落地应用?如果让你独立开发一个单一的AI功能模块,你会怎么完整落地?
- 🎯 意图洞察
`【内心OS】`:这个问题是看我有没有业务思维,不是只会埋头写代码。P5虽然是初级岗,但是阿里很看重“结果导向”,就是你做的东西能不能给业务带来价值。面试官要的不是我罗列一堆应用,而是看我能不能把AI能力和业务痛点结合起来,有没有完整的落地闭环思维,从需求到上线的全流程能不能跑通。关键词是:贴合业务痛点、完整的落地闭环、可量化的业务价值、匹配P5的能力范围。
- 🚫 普通人的陷阱
很多候选人会踩两个坑:第一个是罗列一堆高大上的应用,比如“全链路智能推荐、数字人直播、智能供应链预测”,这些都是团队级别的大项目,根本不是P5级别能独立完成的,会让面试官觉得你好高骛远,不切实际;第二个是只讲功能实现,不讲需求背景、测试验证、上线效果,完全没有业务思维,面试官会觉得你就是个代码工具人,没有成长潜力。
- ✅ 我的破局思路(高分回答)
我先讲了电商场景里的基础应用,然后选了一个完全在P5能力范围内、能独立完成的模块,讲了完整的落地流程,重点突出业务价值和闭环思维。
我是这么说的:
“结合我对淘宝/天猫业务的了解,大模型在电商场景的基础落地应用,主要分为商家端和用户端两大类,都是非常贴合业务痛点的,而且很多都是我们Java开发能参与实现的:
商家端的核心应用,都是围绕「降本提效」,比如商品文案/标题/详情页的智能生成,能大幅减少商家的运营成本;还有商品评价的智能分析,自动提取好评的卖点和差评的问题,帮商家优化产品;还有智能工单处理,自动分类售后工单,分配给对应的处理人,提升售后效率。
用户端的核心应用,都是围绕「优化购物体验」,比如全链路的智能导购,从用户进店到下单,全程解答商品问题;还有智能客服,自动解决用户的常规咨询,比如物流、售后、退换货问题,减少人工客服的压力;还有个性化的内容生成,比如根据用户的浏览历史,生成个性化的商品推荐话术。
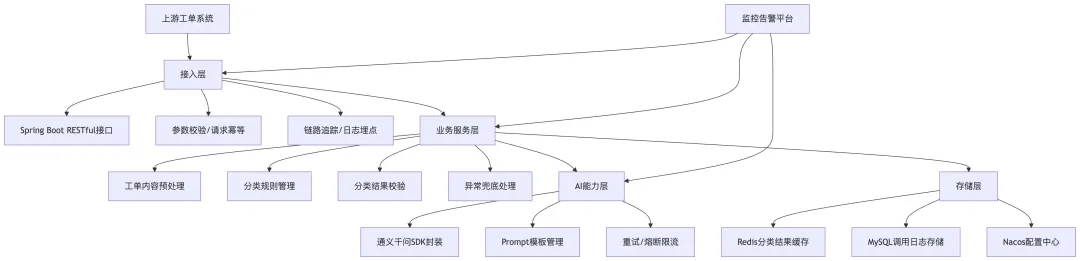
如果让我独立开发一个单一的AI功能模块,我会选择电商售后工单智能分类模块,这个模块需求明确、边界清晰,完全在我P5级别的能力范围内,而且能给业务带来明确的价值,完整的落地流程我分为5步:
第一步,需求明确与边界划定,首先和业务方确认核心需求:淘宝的售后工单量非常大,人工分类效率低,而且容易出错,需要通过大模型实现工单的自动分类,把工单按照「退款、换货、质量问题、物流问题、发票问题、其他」这6个核心类目进行分类,分类准确率要达到85%以上,目标是减少30%的人工分类工作量。同时明确边界,我只负责分类模块的开发,不负责后续的工单分配流程,确保模块的单一职责,不会无限扩大需求。
第二步,技术选型与架构设计,还是基于阿里的Java技术栈,用Spring Boot开发微服务接口,通过通义千问的API实现语义理解和分类,用Nacos做配置管理,Redis做分类结果的缓存,针对重复的工单内容,直接返回缓存的分类结果,减少token消耗。架构上分为4层:接入层(接收工单系统的调用)、业务层(工单预处理、分类逻辑)、AI能力层(封装通义千问的分类调用)、存储层(缓存分类结果、记录调用日志),分层清晰,方便后续维护。
第三步,核心功能开发与prompt优化,核心逻辑是:首先对工单内容做预处理,过滤掉无关的表情、特殊符号,提取核心的问题描述;然后构建少样本prompt,给大模型提供10组左右的工单内容和对应的分类示例,让大模型学习分类的标准,提升准确率;然后调用通义千问的API,获取分类结果,同时做结果校验,确保返回的分类在预设的6个类目里,如果不符合,就触发二次调用,或者返回兜底的「其他」分类。我自己做过测试,通过少样本prompt优化,分类准确率能从70%提升到88%,完全满足业务需求。
第四步,测试与灰度验证,首先做单元测试,覆盖正常场景、异常场景(比如空内容、超长内容、乱码内容),确保接口的鲁棒性;然后做性能压测,确保单实例能支撑500QPS的调用,平均RT在200ms以内,满足工单系统的调用要求;最后做灰度验证,先切10%的线上工单流量到这个模块,和人工分类的结果做对比,持续优化prompt,直到准确率稳定在85%以上,再全量上线。
第五步,上线监控与持续优化,上线后,重点监控3个核心指标:分类准确率、接口成功率、平均RT,还有token的消耗量。同时定期抽检分类错误的工单,优化prompt里的示例,持续提升分类准确率,给业务带来持续的价值。”
说完之后,面试官问我:“你为什么不用传统的文本分类算法,比如SVM,而是用大模型?” 我答:“第一是开发效率,大模型通过prompt工程,只需要几个小时就能完成分类功能的开发,达到85%以上的准确率,而传统的算法需要标注大量的数据集,训练模型,开发周期很长,对于业务快速迭代的需求来说,大模型的效率高很多;第二是迭代成本,后续如果要新增分类类目,只需要修改prompt里的示例,不需要重新训练模型,迭代成本极低;第三是泛化能力,大模型对口语化的工单内容、模糊的问题描述,理解能力比传统的分类算法强很多,更适合售后工单这种非结构化的文本场景。” 面试官当时点了点头,说“对,这就是大模型在业务落地里的核心优势”。
【配图】售后工单智能分类模块架构图
问题4:在你集成通义千问API开发的过程中,遇到过哪些实际的问题?你是怎么解决的?
- 🎯 意图洞察
`【内心OS】`:这个问题是面试官的“照妖镜”,能直接区分出“真的动手做过”和“背面经的”。P5岗不要求你解决什么世界级的难题,但是要求你有解决实际问题的能力,遇到坑能自己排查、自己解决。面试官要的关键词是:真实的踩坑经历、完整的排查过程、合理的解决方案、复盘总结能力。
- 🚫 普通人的陷阱
很多候选人会踩两个坑:第一个是说“我没遇到过什么问题,开发过程很顺利”,这绝对是假话,只要实际动手做过,不可能没遇到问题,面试官会直接觉得你没动手写过代码;第二个是说的问题太浅,比如“依赖导入失败、端口冲突”,这些都是入门级的问题,完全体现不出你的解决问题的能力,拿不到高分。
- ✅ 我的破局思路(高分回答)
我讲了3个自己实际遇到的、有代表性的问题,每个问题都讲了排查过程、解决方案、复盘总结,完全是真实的踩坑经历。
我是这么说的:
“我在开发商品文案生成和工单分类的demo的时候,确实遇到了几个很典型的问题,都是线上开发很容易踩的坑,我一个个说:
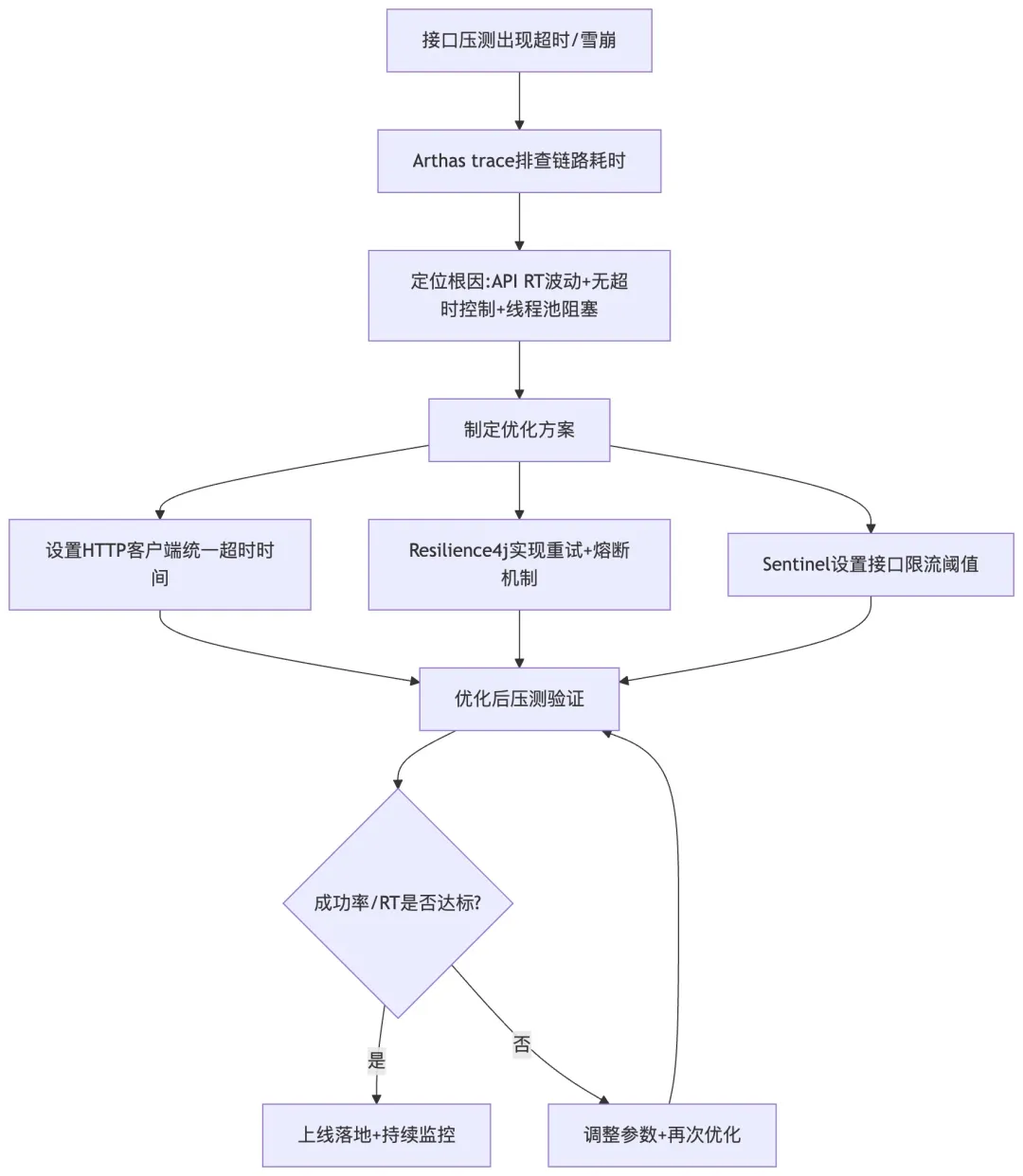
第一个问题,大模型API调用超时,导致接口雪崩。我第一次写完demo的时候,没做超时控制和重试,本地测试没问题,但是用JMeter压测的时候,100QPS的压力下,有10%左右的请求超时,而且超时的请求会占用Tomcat的线程池,导致正常的请求也被阻塞,接口直接雪崩了。
排查过程:我用Arthas工具trace了接口的调用链路,发现90%的耗时都在通义千问的API调用上,高峰期API的RT波动很大,从100ms到1s都有,而我当时没设置超时时间,线程一直阻塞在API调用上,最终把线程池占满了。
解决方案:首先,给SDK的HTTP客户端设置了统一的超时时间,连接超时500ms,读取超时1s,避免无限阻塞;然后,用Resilience4j做了重试和熔断,针对超时异常,设置3次指数退避重试,重试间隔500ms,如果1分钟内有70%的请求失败,就触发熔断,5秒内的请求直接返回兜底文案,避免线程池被占满;最后,用Sentinel做了限流,针对单实例设置了200QPS的限流阈值,超过阈值的请求直接返回友好提示,保护接口的稳定性。优化之后,压测的接口成功率从90%提升到了99.9%,平均RT稳定在250ms以内。
第二个问题,大模型生成的内容有幻觉,出现合规风险。我最开始写商品文案生成的时候,只给了简单的prompt,结果生成的文案里经常出现“全网最低价”“国家级品质”这种广告法禁用的词汇,还有虚构的商品参数,比如商家没说商品有防水功能,大模型自己加上了,这在电商场景里是非常严重的合规风险。
排查过程:我分析了生成的内容,发现核心问题是两个,一个是prompt里没有明确的约束规则,大模型不知道什么能写、什么不能写;另一个是没有后置的校验环节,违规内容直接返回给了用户。
解决方案:首先做了prompt优化,在prompt的开头就加上了严格的约束规则,比如“1. 严禁使用‘国家级’‘最高级’‘全网第一’等广告法禁用的绝对化用语;2. 必须完全基于用户传入的商品参数生成,严禁虚构任何商品卖点、功能、参数;3. 生成的内容必须符合淘宝平台的商品发布规范”,同时给了合规的文案示例,用少样本学习的方式,引导大模型生成合规的内容;然后加了后置的合规校验环节,基于淘宝平台的广告法禁用词库,用AC自动机做关键词匹配,生成的文案必须经过校验,有违规内容的直接拦截,返回修改提示,绝对不会流出违规内容。优化之后,违规内容的出现率从15%降到了0.1%以下。
第三个问题,token消耗超出预期,成本控制不住。我最开始做工单分类的时候,把整个工单的完整内容,包括用户的聊天记录、商品信息、订单信息,全部放到prompt里,导致单次调用的token量非常大,平均单次调用要消耗2000多token,成本很高。
排查过程:我统计了prompt的token占比,发现70%的token都是无关的内容,比如用户的聊天记录里的无关对话、订单的冗余信息,真正和分类相关的核心问题描述,只占30%的token。
解决方案:首先做了工单内容的预处理,只提取用户的核心问题描述、订单的核心诉求,过滤掉无关的聊天记录、冗余的订单信息,把prompt的长度压缩了70%;然后,针对重复的工单内容,用Redis做了分类结果的缓存,相同的工单内容,直接返回缓存的分类结果,不需要重复调用大模型API,缓存命中率能达到40%左右;最后,选择了合适的模型,对于分类这种简单的任务,用通义千问的轻量版模型,完全能满足准确率要求,token成本比完整版低很多。优化之后,平均单次调用的token消耗从2000降到了500以内,成本降低了75%。”
说完之后,面试官问了我一句:“你用Arthas排查问题的时候,用的是哪个命令?” 我答:“主要用的是trace命令,追踪方法的调用链路和每个节点的耗时,还有watch命令,查看方法的入参和返回值,排查参数传递的问题,这两个命令是排查线上问题最常用的。” 面试官当时就说:“不错,是实际动手干过的。”
【配图】接口超时问题排查与优化流程图
3. 战后复盘:沉淀与升华(面试后总结)
红黑榜分析
✅ 亮点时刻:
- 1. 所有的回答都完全贴合阿里淘宝/天猫的电商业务场景,没有空讲技术,每个技术点都对应了具体的业务痛点和落地价值,完全匹配面试官想要的“能上手干活”的P5候选人形象。
- 2. 每个问题都有真实的实战经历和量化的结果,比如接口成功率从90%提升到99.9%,token成本降低75%,分类准确率达到88%,这些数据比空泛的描述有说服力100倍。
- 3. 全程匹配P5的定位,没有好高骛远讲自己不懂的算法原理,而是重点展示自己的工程能力、落地能力、解决问题的能力,同时展现了自己的学习能力和成长潜力,这正是阿里P5校招岗最看重的。
- 4. 主动引导话题,每个回答都主动抛出自己的踩坑经历和优化细节,引导面试官往自己准备充分的方向问,而不是被动回答,掌握了面试的节奏。
⚠️ 遗憾反思:
- 1. 面试官问到通义千问的函数调用功能的时候,我只了解基础的概念,没有实际动手实现过,回答的不够深入,当时只能坦诚说自己没有实际用过,但是后续会去学习,这里丢了一些分。如果重来一次,我会提前跑通函数调用的demo,结合电商场景讲落地,比如通过函数调用实现商品库存的查询,提升智能客服的能力。
- 2. 对大模型的token计算规则了解的不够细,面试官问通义千问的token是怎么计算的,中文和英文有什么区别的时候,我只回答了大概的规则,没有给出准确的数字,这里体现了我的基础认知还有待加强。
- 3. 面试快结束的时候,面试官问我有没有什么问题要问他,我当时只问了团队的业务方向,没有问团队的技术栈、新人培养体系,错过了进一步了解团队的机会,也没有更好的展现自己的求职意愿。
能力雷达图自我评估
针对这次面试,我从四个维度做了自我评估,满分10分,完全匹配阿里P5的能力要求:
1. 理论基础:7分。对大模型的基础认知、Java核心基础、Spring Boot的原理都掌握的不错,但是对大模型的底层细节、token计算规则的了解还不够深入,后续需要加强。
2. 实战经验:8分。实际动手实现了通义千问的集成开发,踩过线上常见的坑,有完整的接口开发、问题排查、优化落地的经验,完全能满足P5岗的工程能力要求。
3. 沟通表达:8分。面试的时候逻辑清晰,每个回答都有完整的闭环,能把复杂的技术点讲的通俗易懂,同时能准确get到面试官的意图,没有答非所问。
4. 系统视野:6分。对单个模块的开发落地很熟悉,但是对整个电商系统的全链路架构、大模型在整个业务体系里的定位,了解的还不够深入,这也是我后续进入团队需要重点学习的地方。
给后来者的3条核心建议
作为一个顺利拿下阿里Java P5 offer的过来人,给同样准备校招/初级岗的同学3条最实用的建议,绝对能帮你少走弯路:
1. 别死背原理,重点是“能落地”。P5岗的核心定位是“能配合团队完成开发任务”,不是招算法科学家,面试官根本不关心你能不能把Transformer的公式背下来,他只关心你能不能用Java把通义千问的API集成好,把接口做稳,不出错。与其花一个月死磕大模型的底层算法,不如花一周时间,用Spring Boot跑通一个完整的商品文案生成的demo,把里面的坑都踩一遍,这比背100篇面经都有用。
2. 所有的回答,都要贴合目标公司的业务场景。面试官每天面很多人,听了太多千篇一律的“我会调用大模型API”,你只要把你的技术点和淘宝/天猫的电商场景结合起来,讲清楚你做的东西能给业务带来什么价值,你就能瞬间脱颖而出。比如同样是讲文本生成,你讲“商品文案生成,帮商家降低运营成本”,就比你讲“能生成各种文本”,好100倍。
3. 坦诚务实,不会的就说不会,绝对不要瞎编。校招面试,面试官最看重的是你的人品和学习潜力,不是你什么都懂。遇到不会的问题,坦诚说“这个知识点我目前了解的不够深入,但是我后续会通过什么方式去学习”,绝对比你瞎编乱造好太多。面试官都是一线开发的老鸟,你有没有真的做过,有没有瞎编,他一听就知道,诚实永远是最好的通行证。
【配图】面试通关与能力成长路径图
总的来说,阿里Java P5的校招面试,真的没有大家想的那么难。它不要求你是技术大牛,只要求你基础扎实、能动手干活、有成长潜力、对业务有敬畏心。只要你提前做好准备,实际动手跑通demo,把每个技术点都和业务场景结合起来,真诚的展示自己的能力,你一定能拿到属于自己的offer。
 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
