【2026面试绝杀】OpenClaw + AI Agent面试八股文|160+道真题,入门到源码全覆盖
- 2026-07-18 06:37:21
OpenClaw是什么?是一款能实际执行任务、跨平台使用的实用型 AI 个人助手。

为什么这么火?虽然是一个“工程学的集大成者”,而非“科学上的突破”,但它精准地击中了国内用户对于“门槛”和“所有权”的渴望。OpenClaw 让那些本就可以被流程化的任务,实现了更高程度的自动化。它迈出了从 “AI 玩具” 到 “实用工具” 的关键一步,为 AI 拓展了更多应用可能。AI 的未来发展方向,并非变得更擅长聊天,而是变得更擅长交付结果。

OpenClaw用274K Stars 证明了一件事:人们不只想和 AI 聊天,更想让 AI 替自己干活。
“OpenClaw 和 ChatGPT 的本质区别在于——ChatGPT是对话工具,OpenClaw是执行框架。前者给你答案,后者帮你干活。”
备考前言:2026年AI Agent工程师岗位需求暴涨25%,坐拥274K+GitHub Stars的OpenClaw,已然成为面试官必问的“新核心八股”。 |
一、OpenClaw基础核心概念
本章节为面试开场必考题,答错直接拉低印象分,所有答案均核对OpenClaw官方文档与源码,杜绝错误表述,按基础、进阶、高级、源码级各5题排布,共20题。
基础级(Q1-Q5,面试开场高频)
How OpenClaw works?WhatsApp / Telegram / Slack / Discord / Google Chat / Signal / iMessage / BlueBubbles / IRC / Microsoft Teams / Matrix / Feishu / LINE / Mattermost / Nextcloud Talk / Nostr / Synology Chat / Tlon / Twitch / Zalo / Zalo Personal / WebChat│▼┌───────────────────────────────┐│ Gateway ││ (control plane) ││ ws://127.0.0.1:18789 │└──────────────┬────────────────┘│├─ Pi agent (RPC)├─ CLI (openclaw …)├─ WebChat UI├─ macOS app└─ iOS / Android nodeshttps://github.com/openclaw/openclaw
Q1:OpenClaw到底是什么?用一句话精准概括
A:OpenClaw是由Peter Steinberger开发的开源本地优先自主AI Agent框架,可部署在本地设备,通过主流消息平台对接大模型,让LLM从“单纯对话”升级为“自主执行真实任务”,相当于专属本地数字员工。
Q2:OpenClaw的项目前身是什么?
A:原名迭代顺序为Clawdbot → Moltbot → OpenClaw,原文提及的Warelay非官方标准命名,属于早期非公开迭代代号,面试仅需回答官方公开更名记录即可。
Q3:OpenClaw和ChatGPT的核心区别是什么?【面试必问】
A:ChatGPT是对话交互工具,仅能输出文本答案,无实际执行能力;OpenClaw是任务执行框架,具备工具调用、文件操作、命令执行、跨平台消息推送等实操能力,简单总结:ChatGPT给答案,OpenClaw直接干活。
加分话术:二者定位完全不同,ChatGPT聚焦自然语言交互,OpenClaw聚焦自主任务落地,是轻量化、开箱即用的Agent落地方案。
Q4:OpenClaw支持接入哪些主流消息平台?
A:原生支持20+平台,核心包括WhatsApp、Telegram、Discord、Slack、飞书、钉钉、Signal、iMessage、MS Teams、LINE等,通过各平台官方SDK实现一键对接,无需额外开发适配。
Q5:OpenClaw的开源许可证是什么?有什么权限?
A:采用MIT License,属于行业宽松型开源协议,允许个人免费使用、商业二次开发、代码修改与再分发,无严苛版权限制,适配个人学习与企业小范围落地。
进阶级(Q6-Q10,技术面中期考点)
Q6:OpenClaw的核心技术栈是什么?
A:核心运行时依赖Node.js v22及以上版本,采用TypeScript编写保障类型安全;包管理兼容npm/pnpm/bun;消息通道对接各平台专属SDK,比如WhatsApp用Baileys、Telegram用grammY、Discord用discord.js、Slack用Bolt。
Q7:OpenClaw强调的“本地优先”具体指什么?
A:所有核心数据(用户记忆、会话历史、配置文件、任务记录)默认存储在本地~/.openclaw/目录,以Markdown和JSON格式保存,不依赖任何云端数据库,数据完全私有化存储,无云端传输泄露风险,离线状态也能正常运行核心功能。
Q8:OpenClaw支持哪些大模型?是否绑定特定厂商?
A:采用模型无关设计,不绑定任何LLM厂商,兼容市面上主流大模型,包括GPT系列、Claude、Gemini、DeepSeek、Llama开源系列、Minimax等,同时支持OpenRouter统一调用,通过固定的provider/model格式灵活配置切换。
Q9:OpenClaw有哪几种主流部署方式?
A:共三种标准化部署方案,适配不同使用场景:
1)系统服务部署:执行openclaw onboard --install-daemon命令,适配macOS的launchd、Linux的systemd;
2)Docker容器化部署,打包环境一键运行,避免环境依赖问题;
3)远程服务器部署:Linux服务器+Tailscale/SSH隧道,实现远程无感操控。
Q10:OpenClaw的核心项目愿景是什么?
A:官方VISION.md文件明确核心目标——“the AI that actually does things”,打造真正能落地执行实际任务的AI助手,而非单纯的对话机器人,当前开发优先级为安全默认配置、漏洞修复与首次运行体验优化。
高级(Q11-Q15,深度技术面)
Q11:OpenClaw核心代码仓库目录结构是怎样的?
A:核心目录分工明确,各司其职:extensions/存放各消息平台插件;skills/为内置技能模板目录;docs/存放官方全量文档;apps/对应macOS/iOS/Android多端客户端;Swabble/为Swift语音唤醒专属模块。
Q12:什么是PI Agent?在OpenClaw中承担什么角色?
A:PI Agent(pi-mono)是OpenClaw内嵌的Agent执行核心引擎,主要负责大模型调用调度、工具执行逻辑流转;而会话管理、工具发现、多平台消息路由等上层逻辑,由OpenClaw主框架控制,二者实现逻辑解耦,提升框架扩展性。
Q13:OpenClaw的模型标识符如何解析?
A:采用固定provider/model格式,系统按首个“/”分割解析参数,比如openrouter/moonshotai/kimi-k2中,provider为openrouter,model为moonshotai/kimi-k2;若省略provider,系统自动调用配置文件中的默认厂商。
Q14:Workspace和State Dir的核心区别是什么?
A:二者存储内容与用途完全不同:Workspace(默认~/.openclaw/workspace)是Agent核心工作目录,存放AGENTS.md、SOUL.md等行为配置文件;State Dir(~/.openclaw/)为系统数据目录,存放基础配置、API凭证、会话历史等核心系统数据,相互独立互不干扰。
Q15:OpenClaw的Companion App包含哪些端?有什么特殊能力?
A:覆盖macOS(SwiftUI)、iOS(SwiftUI)、Android(Kotlin+Jetpack Compose)三端原生客户端,通过Gateway WebSocket与主框架连接,可调用设备原生硬件能力,包括摄像头、屏幕录制、定位、语音输入,大幅拓展Agent的交互与执行维度。
源码级(Q16-Q20,大厂源码面必考)
Q16:OpenClaw的Workspace Bootstrap核心文件有哪些?
A:核心引导文件共6个,分别是AGENTS.md(行为规则)、SOUL.md(人格语气)、TOOLS.md(工具说明)、BOOTSTRAP.md(首次运行流程)、IDENTITY.md(Agent名称)、USER.md(用户信息);系统运行时空文件自动跳过,超大文件自动截断,避免内存过载。
Q17:OpenClaw的Session会话数据存储格式与路径是什么?
A:会话数据采用JSONL格式逐行存储,标准路径为~/.openclaw/agents/
Q18:OPENCLAW_PROFILE环境变量的作用是什么?
A:当设置该变量为非default值时,系统会自动将Workspace路径切换为~/.openclaw/workspace-
Q19:skipBootstrap配置的作用是什么?
A:在配置文件中设置{agent: {skipBootstrap: true}}后,系统会禁止自动创建Bootstrap引导文件,适用于高级用户自行管理Workspace、自定义全套配置的场景,避免系统默认文件覆盖自定义内容。
Q20:OpenClaw沙箱Sandbox seed的安全限制有哪些?
A:沙箱初始化时仅复制Workspace内的普通文件,所有指向Workspace外部的软链接、硬链接均直接忽略,从根源防止沙箱逃逸,彻底避免Agent非法访问宿主系统核心文件、篡改系统数据。
二、OpenClaw五大核心组件 Q&A
面试官提问“介绍OpenClaw架构”,按本章五大组件顺序作答,逻辑清晰、踩分点全,是面试高分核心答法,共20题,分四个难度层级,无留白、无概括。
基础级(Q1-Q5)
Q1:OpenClaw五大核心组件分别是什么?
A:Gateway(网关)、Brain(大脑)、Memory(记忆)、Skills(技能)、Heartbeat(心跳),五大组件模块化设计,职责完全解耦。
组装系统提示词 -> 发送给 LLM -> 解析响应-> 执行工具调用 -> 循环直到产出最终答案
Q2:Gateway组件的核心职责是什么?为何不做推理?
A:Gateway是长期运行的WebSocket服务器(默认localhost:18789),仅负责多平台消息的接收、分发与路由,不参与任何LLM推理。这种设计实现消息通道与Agent核心逻辑完全解耦,更换消息平台不影响推理流程,大幅提升系统模块化与扩展性。
Q3:OpenClaw记忆系统为何选用Markdown,而非传统数据库?
A:四大核心原因:
1)本地优先,无需额外部署数据库基础设施,降低使用门槛;
2)人类可读可直接编辑,方便用户自定义Agent记忆内容;
3)支持Git版本控制,可回溯记忆修改记录;
4)与Workspace工作目录天然融合,完全适配本地存储逻辑。
Q4:什么是Heartbeat?和普通定时任务有什么区别?
A:Heartbeat是Agent的主动意识模块,每30分钟自动触发一次,批量检查待处理任务。和普通定时任务的核心区别:Heartbeat运行在主会话中,拥有完整对话上下文与长期记忆,可智能判断是否执行任务;普通定时任务无上下文感知,仅机械执行固定指令,无自主判断能力。
Q5:OpenClaw的Skills技能存储格式是什么?
A:每个Skill对应独立文件夹,内含SKILL.md核心文件,文件由两部分组成:上方YAML元数据(名称、描述、适用场景)+下方Markdown自然语言指令,社区ClawHub平台已有5000+现成技能,可直接复用。
进阶级(Q6-Q10)
Q6:Gateway的通信协议是什么?连接生命周期是怎样的?
A:采用WebSocket传输JSON文本帧,完整生命周期:1)客户端首帧必须发送connect请求;2)Gateway验证后返回hello-ok,包含在线状态与健康快照;3)后续正常收发请求与事件;4)非JSON或非connect的首帧,系统直接断开连接保障安全。
Q7:OpenClaw Memory的两层架构分别存储什么?加载策略是什么?
A:两层记忆架构分工明确:
1)memory/YYYY-MM-DD.md:每日追加式短期笔记,系统启动时仅加载当天和昨天的内容,控制上下文长度;
2)MEMORY.md:长期记忆,存储用户偏好、固定约定等持久信息,仅在私聊主会话加载,群组上下文不加载。
Q8:Skills从哪些位置加载?优先级如何?
A:共三个加载路径,Workspace优先级最高:1)Bundled:随安装包自带的基础技能;2)Managed/local:本地~/.openclaw/skills目录;3)Workspace:
Q9:Gateway 分发哪些类型的核心事件?
A:共六大核心事件:agent(Agent推理流事件)、chat(聊天消息事件)、presence(在线状态事件)、health(健康检查事件)、heartbeat(心跳触发事件)、cron(定时任务触发事件)。
Q10:Heartbeat 的“静默回复”机制是什么?
A:Heartbeat运行后,若无需要通知用户的事项,Agent自动回复HEARTBEAT_OK,该消息为静默消息,不会推送给用户,完全无感知;仅当有重要待办、异常情况时,才发送用户可见消息,避免频繁打扰。
高级(Q11-Q15)
Q11:OpenClaw 的 Memory Flush 机制如何工作?
A:当会话token数量接近contextWindow - reserveTokensFloor - softThresholdTokens阈值时,系统发送静默指令,要求Agent将重要信息写入MEMORY.md,随后清理短期对话历史;每个压缩周期仅触发一次,工作区为只读模式时自动跳过,不影响系统运行。
Q12:OpenClaw 的向量搜索支持哪些Embedding提供商?自动选择顺序是什么?
A:自动选择优先级顺序:
1)local(本地GGUF模型);
2)openai(OpenAI嵌入模型);
3)gemini;
4)voyage;
5)mistral;额外支持ollama但不参与自动选择,若所有提供商均未配置,记忆搜索功能自动禁用。
Q13:Heartbeat 和 Cron 分别适合什么场景?
A:Heartbeat适合批量定期检查、需要上下文感知的任务,比如合并检查收件箱+日历+通知;Cron适合精确定时、无上下文依赖的任务,比如每周一9点生成周报、一次性定时提醒。
Q14:OpenClaw 的 QMD 后端是什么?它如何增强 Memory Search?
A:QMD是实验性本地搜索工具,通过memory.backend = "qmd"启用,结合BM25关键词检索+向量语义检索+重排序,完全本地运行;搜索失败时自动回退到内置SQLite管理器,兼顾检索精度与稳定性。
Q15:Gateway 的 Wire Protocol 有什么安全机制?
A:四大安全机制:
1)支持配置网关令牌,连接需校验令牌匹配;
2)所有连接必须签名connect随机值;
3)v3签名绑定平台+设备类型,重连校验一致性;
4)副作用方法需幂等键,服务端短期去重,防止重复执行。
源码级(Q16-Q20)
Q16:OpenClaw 的 Agent Loop 完整执行流程是怎样的?
A:1)RPC验证参数、解析会话,持久化会话元数据;
2)解析模型配置、加载技能快照;
3)序列化运行执行引擎,构建会话、订阅事件;
4)将核心事件桥接为工具、助手、生命周期流,完成完整推理执行循环。
Q17:OpenClaw 的 Plugin Hook 系统有哪些关键 Hook 点?
A:核心钩子包括:模型解析前、提示词构建前、工具调用前后、工具结果持久化、会话启停、网关启停、消息接收与发送、记忆压缩前后,支持全方位自定义扩展。
Q18:OpenClaw 的 Queue Mode 有哪些?streaming 时如何处理新消息?
A:三种队列模式:
1)steer:工具调用后检查新消息,立即切入新消息;
2)followup:当前轮次结束后处理新消息;
3)collect:收集所有消息后一次性处理,适配不同交互场景。
Q19:OpenClaw Multi-Agent 路由中,单个Agent的完整隔离范围是什么?
A:每个Agent拥有完全独立的:1)Workspace工作目录;2)Agent系统目录(含认证配置);3)会话存储目录;4)独立技能配置,认证凭证不共享,彻底实现多Agent隔离。
Q20:OpenClaw 的 Block Streaming 和 Coalesce 机制如何工作?
A:Block Streaming默认关闭,启用后按段落/句子分块发送;Coalesce机制基于空闲时间合并流式分片,减少刷屏;非Telegram平台需手动开启该功能,适配不同消息平台的展示逻辑。
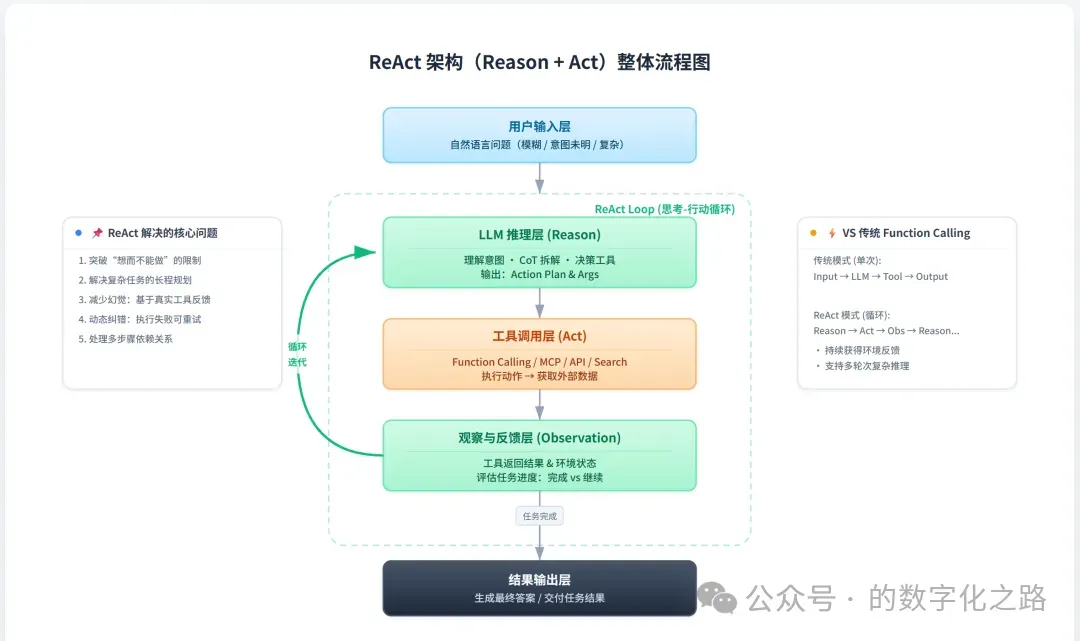
三、ReAct框架 Q&A(20题,Agent核心推理必考)
ReAct是所有AI Agent面试的TOP1考点,必须吃透原理、执行流程与同类方案区别,本章20题全覆盖,面试可直接背诵。
基础级(Q1-Q5)
Q1:ReAct是什么的缩写?核心思想是什么?
A:ReAct=Reasoning(推理)+Acting(执行),核心思想是让LLM在推理和行动之间交替循环,通过行动结果反馈调整推理策略,直至完成任务,实现“思考+动手”的闭环。
Q2:ReAct循环的三个核心步骤是什么?
A:
1)Thought:LLM分析当前状态,推理下一步计划;
2)Action:执行工具调用、API查询等实际操作;
3)Observation:收集执行结果,作为下一轮推理输入。
Q3:ReAct和纯CoT的最大区别是什么?
A:CoT仅在模型内部做线性推理,无法与外部环境交互,极易产生幻觉;ReAct可通过Action调用外部工具获取真实数据,结合Observation验证推理,幻觉风险大幅降低,具备实操能力。
Q4:ReAct循环的终止条件有哪些?
A:三种终止场景:
1)Agent成功生成最终答案,任务完成;
2)达到预设最大迭代次数,强制终止;
3)遇到无法修复的执行错误,终止循环。
Q5:为什么说ReAct能有效减少幻觉?
A:ReAct构建了“事实获取-推理-验证”的闭环,不完全依赖模型内部知识,通过外部工具获取真实数据,用执行结果校验推理逻辑,从根源降低虚构内容的概率。
进阶级(Q6-Q10)
Q6:CoT、ToT、ReAct、Reflexion的关系是什么?
A:四者并非互斥关系,而是互补升级:CoT是基础线性推理,ToT是多路径树状推理,ReAct是推理+行动结合,Reflexion是自我反思优化;ReAct可在Thought阶段嵌入CoT,失败后触发Reflexion自检。
Q7:OpenClaw中的Brain组件如何实现ReAct循环?
A:Brain先组装包含工具列表的系统提示词,发送给LLM;解析LLM输出的推理与调用指令,执行对应工具;将工具结果返回LLM,开启下一轮循环,直至LLM输出最终回复。
Q8:ReAct循环中,哪个环节更消耗Token?如何优化?
A:Action+Observation环节更耗Token,因为包含大量工具返回数据。优化方式:1)限制工具返回结果长度;
2)设置最大迭代次数;
3)开启记忆压缩机制;
4)对大结果做摘要处理。
Q9:Plan-and-Solve和ReAct有什么区别?
A:Plan-and-Solve先生成完整计划再执行,效率高但灵活性差,适合步骤固定的任务;ReAct边思考边执行,可动态调整策略,灵活性强,适合不确定性高的复杂任务。
Q10:ReAct循环中工具执行失败,Agent该如何处理?
A:标准处理逻辑:
1)将错误信息作为Observation反馈给LLM;
2)LLM分析失败原因,调整策略;
3)尝试重试或更换替代方案;
4)多次失败后主动向用户请求帮助,实现自愈。
高级(Q11-Q15)
Q11:OpenClaw Agent Loop中,tool event的生命周期事件有哪些?
A:工具事件分三个阶段:tool start(开始执行)、tool update(执行中进度更新)、tool end(执行完成),结果会先做脱敏、长度清理,再记录日志、推送反馈。
Q12:ReAct多步推理中的错误传播问题是什么?如何缓解?
A:错误传播指某一步推理出错,后续基于错误结果继续执行,误差逐级放大。缓解方式:1)加入Reflexion自检机制;
2)设置置信度阈值;
3)关键步骤开启人工审批;
4)控制最大迭代次数。
Q13:OpenClaw的Compaction机制与ReAct循环有什么关系?
A:Compaction机制是ReAct循环的上下文保障,当循环消耗Token接近窗口上限时,自动触发记忆压缩,清理冗余历史、保存核心信息,避免上下文溢出,保障循环持续运行。
Q14:什么是Agent流式转向?OpenClaw如何实现?
A:流式转向指Agent正在流式推理时,用户发送新消息切换任务。OpenClaw在steer模式下,每次工具调用后检查消息队列,有新消息则跳过当前工具执行,直接切入新任务。
Q15:ReAct框架的核心局限性是什么?
A:局限性:1)迭代次数过多会导致Token成本飙升;2)复杂任务易出现执行路径混乱;3)依赖LLM的指令遵循能力;4)无长期记忆时,重复任务会重复推理,效率偏低。
源码级(Q16-Q20)
Q16:OpenClaw中runEmbeddedPiAgent的序列化策略是什么?
A:采用会话专属通道+全局通道双重序列化,防止工具与会话竞争,保障会话历史一致性,消息通道可通过队列模式适配该序列化逻辑。
Q17:OpenClaw的System Prompt由哪些部分组装?
A:由四部分组成:基础提示词、技能提示词、引导文件上下文、单次运行覆盖配置,同时强制适配模型限制与压缩预留Token。
Q18:OpenClaw中agent.wait和Agent timeout的默认值是多少?
A:agent.wait默认超时30秒,仅等待不终止Agent;Agent运行超时默认600秒(10分钟),超时后强制终止执行,防止资源占用。
Q19:OpenClaw的消息工具重复抑制机制是什么?
A:系统追踪消息工具发送记录,若最终回复文本包含已发送内容,自动移除重复部分,避免用户收到重复消息,提升交互体验。
Q20:OpenClaw Agent Loop可提前结束的节点有哪些?
A:四个提前结束场景:1)Agent运行超时强制终止;2)外部取消信号触发;3)网关断开连接;4)RPC等待超时,仅停止等待不终止Agent。
四、通用AI Agent四大基础组件 Q&A
本章节为AI Agent通用基础考点,不局限于OpenClaw,所有Agent岗位面试均会涉及,核心公式:Agent = LLM(大脑)+ Planning(规划)+ Memory(记忆)+ Tool Use(工具),共20题。
基础级(Q1-Q5)
Q1:AI Agent的标准核心公式是什么?
A:Agent = LLM(大脑)+ Planning(规划)+ Memory(记忆)+ Tool Use(工具),四大组件缺一不可。
Q2:AI Agent和传统Chatbot的核心区别是什么?
A:传统Chatbot仅支持单/多轮对话,无自主执行能力;
AI Agent具备自主规划、长短期记忆、工具调用能力,可独立完成多步骤目标导向任务,无需人工逐步骤干预。
Q3:Agent的“自主性”体现在哪五个方面?
A:
1)无需逐步指导,独立运作;
2)感知环境变化并调整策略;
3)目标导向主动执行;
4)自然交互适配人类;
5)从历史任务中学习优化。
Q4:Agent短期记忆和长期记忆的区别是什么?
A:短期记忆是上下文窗口内的对话历史,随会话结束消失;长期记忆是持久化存储的知识,跨会话保留,支持语义检索调用。
Q5:Agent为什么必须具备工具调用能力?
A:LLM训练数据有截止日期,无法获取实时信息,且不擅长精确计算、系统操作;工具调用弥补这些短板,让Agent能对接外部系统、完成实操任务。
进阶级(Q6-Q10)
Q6:Agent Planning模块的主流方法有哪些?
A:主流方法:
1)CoT线性推理;
2)ToT树状多路径推理;
3)Reflexion自我反思;
4)Plan-and-Solve先规划后执行,适配不同复杂度任务。
Q7:Agent记忆系统的常见设计方案有哪些?
A:1)上下文窗口直接存储;
2)向量数据库语义检索;
3)关系型数据库存结构化数据;
4)本地文件(Markdown/JSON)存储;
5)混合检索方案。
Q8:什么是Agentic AI?核心特征是什么?
A:Agentic AI是具备自主性的AI系统,核心从“回答问题”升级为“完成目标”,特征:自主性、反应性、主动性、社交能力、学习能力。
Q9:Agent Planning模块如何处理任务执行失败?
A:1)任务分解失败回退,更换分解策略;
2)执行失败重规划,调整步骤;
3)触发Reflexion反思原因;
4)关键节点请求人工介入。
Q10:评估Agent系统好坏的核心指标有哪些?
A:任务完成率、执行步骤效率、Token消耗成本、幻觉发生率、系统鲁棒性、端到端响应延迟。
高级(Q11-Q15)
Q11:OpenClaw如何通过文件塑造Agent人格?
A:通过引导文件定义:SOUL.md定义语气人格,AGENTS.md定义行为规则,USER.md定义交互方式,IDENTITY.md定义名称风格,会话启动时自动注入上下文。
Q12:Agent上下文管理的核心挑战与解决方案?
A:核心挑战是上下文窗口有限,解决方案:记忆压缩、关键信息持久化、RAG按需检索、长文本摘要、分层记忆加载。
Q13:什么是Agent幻觉-行动放大问题?
A:指Agent基于幻觉做出错误推理,进而通过工具执行错误操作,后果从文本幻觉升级为实际系统操作风险,危害远大于纯对话幻觉。
Q14:Agent人机协同(Human-in-the-loop)的设计模式有哪些?
A:关键操作审批、信息不足主动询问、异常升级通知、长任务定期 checkpoint 汇报。
Q15:如何设计Agent的工具权限策略?
A:采用白名单机制、分级权限(只读自动执行,写入需确认)、沙箱隔离、调用频率限制、全流程审计日志。
源码级(Q16-Q20)
Q16:OpenClaw工具权限策略在源码中如何实现?
A:核心工具默认可用,受权限策略约束,TOOLS.md仅做使用指南,额外工具通过配置白名单启用,危险工具需手动开启。
Q17:OpenClaw会话管理器在Agent Loop中的作用?
A:解析工作空间、加载技能、注入引导文件、获取会话锁、完成流式输出前的全部准备工作。
Q18:before_prompt_build钩子可注入哪些内容?
A:动态前置上下文、系统提示词替换、前后置稳定指导信息,适配动态场景与固定规则配置。
Q19:OpenClaw执行命令的信任模型是什么?
A:默认宿主优先,沙箱未激活时自动回退到宿主执行,沙箱模式仅隔离高风险操作,兼顾易用性与安全性。
Q20:tool_result_persist钩子的作用是什么?
A:工具结果持久化前做处理,包括敏感信息脱敏、结果长度压缩、格式标准化,保障数据安全与存储效率。
五、Function Calling/Tool Calling Q&A(工具调用核心)
Function Calling是Agent实现“动手干活”的核心桥梁,本章20题覆盖基础原理、执行流程、异常处理、源码细节,解决面试所有工具调用相关问题。
基础级(Q1-Q5)
Q1:什么是Function Calling/Tool Calling?
A:让LLM输出结构化工具调用指令(JSON格式),由运行时环境执行,结果返回LLM继续推理,形成“决策-执行-反馈”闭环。
Q2:Function Calling的标准四步流程是什么?
A:1)工具注册(定义名称、描述、参数);2)LLM判断是否调用工具;3)LLM输出结构化调用指令;4)运行时执行工具,返回结果给LLM。
Q3:LLM会自己执行函数吗?
A:不会,LLM仅负责决策“调用什么工具、传什么参数”,实际执行由框架运行时完成,LLM是指挥官,运行时是执行者。
Q4:Tool Schema包含哪些核心字段?
A:工具名称、功能描述、参数JSON Schema(参数名、类型、是否必填、示例)。
Q5:工具调用的核心价值是什么?
A:打破LLM数据截止日期限制,获取实时信息;弥补LLM精确计算、系统操作短板;实现Agent与外部系统对接,完成实操任务。
进阶级(Q6-Q10)
Q6:什么是并行工具调用?适用场景是什么?
A:LLM单次输出多个工具调用指令,运行时并行执行,适合无依赖关系的任务,比如同时查询天气、日历、新闻。
Q7:如何设计高质量的工具描述?
A:描述精准具体,明确功能边界;参数说明清晰,标注类型与示例;说明异常场景,提升LLM调用准确率。
Q8:Tool Calling和RAG的关系是什么?
A:RAG是特殊的Tool Calling,检索功能相当于一个专属工具,Agent通过工具调用触发RAG检索,获取精准知识生成回答。
Q9:OpenClaw内置核心工具有哪些?
A:read读文件、exec执行命令、edit编辑文件、write写文件,均受权限策略管控,保障操作安全。
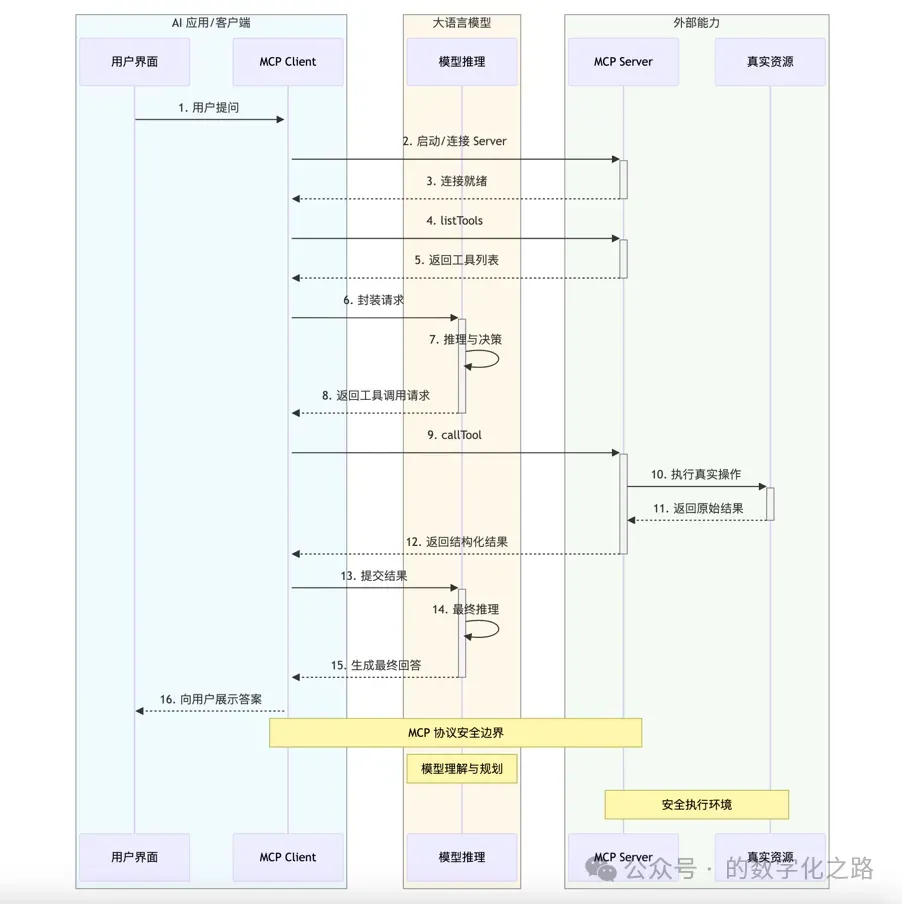
Q10:什么是MCP协议?
A:Model Context Protocol,由Anthropic提出,标准化Agent与工具、数据源的连接,实现工具即插即用,类似USB接口统一适配外设。
高级(Q11-Q15)
Q11:什么是工具调用幻觉?如何防范?
A:幻觉指LLM调用不存在的工具、传错误参数,防范方式:严格Schema校验、工具名白名单、参数强校验、调用频率限制。
Q12:OpenClaw工具结果清理机制是什么?
A:结果记录前做长度截断、敏感信息脱敏、大文件压缩,避免数据泄露与存储过载。
Q13:结构化输出与Function Calling的关系?
A:Function Calling是结构化输出的特殊场景,结构化输出是LLM按指定格式返回数据,Function Calling则是返回工具调用指令。
Q14:OpenClaw扩展插件如何拓展工具能力?
A:通过TypeScript插件模块实现,对接各平台能力,注册到网关生命周期,新增专属工具,比如飞书插件支持文档、表格操作。
Q15:工具调用错误处理的最佳实践?
A:区分可重试/不可重试错误、错误信息返回LLM、指数退避重试、备用工具降级、超时控制。
源码级(Q16-Q20)
Q16:before_tool_call和after_tool_call钩子的用途?
A:前者用于调用前参数校验、加认证、日志记录;后者用于结果脱敏、格式转换、性能统计。
Q17:OpenClaw消息重复抑制对工具调用的影响?
A:自动识别已发送消息,移除回复中的重复内容,避免用户收到重复通知,优化交互体验。
Q18:Lobster工作流与工具调用的交互逻辑?
A:Lobster作为工具调用,返回需审批标识时,Agent暂停执行,等待用户审批通过后恢复,保障高风险操作安全。
Q19:OpenClaw网关如何校验工具调用?
A:通过TypeBox Schema定义协议,入站指令强制校验,不符合格式直接拒绝,保障调用合规。
Q20:OpenClaw执行命令的路由逻辑?
A:默认沙箱优先,沙箱未激活则回退到宿主执行,隐式调用遵循相同逻辑,用户可手动配置路由规则。
六、Multi-Agent与协议标准化 Q&A
MCP、A2A是2026年Agent面试新增热点,本章20题覆盖协议原理、多Agent架构、隔离机制,紧跟行业考情。
基础级(Q1-Q5)
Q1:MCP和A2A分别是什么?
A:MCP是Model Context Protocol,标准化Agent与工具连接;A2A是Agent-to-Agent Protocol,标准化Agent间协作通信。
Q2:MCP和A2A是互补还是替代关系?
A:互补关系,MCP解决Agent对外连接问题,A2A解决Agent对内协作问题,生产级系统通常二者结合使用。
Q3:什么是Multi-Agent系统?
A:多个独立Agent分工协作,共同完成复杂任务的系统,每个Agent具备专属专长,通过协议通信协同。
Q4:用类比解释MCP协议?
A:MCP类似USB接口,统一工具连接标准,无需为每个工具开发专属连接器,实现即插即用。
Q5:2026年Multi-Agent行业趋势是什么?
A:协议标准化、协作流程规范化、落地场景多元化,Gartner预测40%商业应用将集成专属Agent。
进阶级(Q6-Q10)
高级(Q11-Q15,深度技术面)
Q11:MCP协议的核心三层架构是什么?
A:MCP分为传输层、会话层、能力层,传输层负责底层通信(WebSocket/HTTP/Stdio),会话层负责连接鉴权与心跳,能力层负责工具声明、调用、事件通知,三层解耦保障兼容性与扩展性。
Q12:A2A协议解决了Multi-Agent的哪些痛点?
A:解决三大核心痛点:1)跨框架Agent通信壁垒,不同框架开发的Agent可标准化交互;2)任务分工混乱,明确主从/协作/分工角色;3)协作无共识,通过协议统一任务流转、结果反馈规则,避免重复执行与冲突。
Q13:Multi-Agent系统的主流协作模式有哪些?
A:四种主流模式:1)主从模式(主控Agent分配任务,执行Agent完成);2)扁平协作(Agent平等沟通,自主分工);3)分层架构(高层做规划,底层做执行);4)蜂巢模式(多Agent并行处理子任务,汇总结果),OpenClaw默认支持主从+扁平双模式。
Q14:Multi-Agent部署的核心难点是什么?OpenClaw如何解决?
A:核心难点是隔离性、资源占用、通信延迟;OpenClaw通过单网关多实例、独立工作空间、轻量化进程、本地网关通信解决,无需额外部署中间件,资源占用远低于传统多框架部署。
Q15:MCP协议相比自定义工具接口,优势是什么?
A:1)标准化,无需重复开发适配逻辑;2)跨框架兼容,支持LangChain、CrewAI、OpenClaw互通;3)自带安全鉴权、心跳保活;4)工具动态发现,即插即用;5)社区生态完善,现成工具库丰富。
源码级(Q16-Q20,大厂源码面必考)
Q16:OpenClaw的MCP适配器实现逻辑是什么?
A:通过内置MCP客户端模块,对接标准MCP服务端,将外部MCP工具转换为OpenClaw原生Skill,自动注册到技能列表,权限沿用OpenClaw内置权限策略,无需额外配置。
Q17:OpenClaw多Agent路由的消息分发规则源码逻辑?
A:网关根据消息来源ID、会话标识、Agent配置的路由规则,匹配目标Agent,消息进入对应Agent的独立队列,按队列模式处理,不同Agent队列完全隔离,不抢占资源。
Q18:A2A协议在OpenClaw中的通信载体是什么?
A:基于网关内部WebSocket通道,采用JSON-RPC格式通信,携带Agent标识、任务ID、权限令牌,本地多Agent通信无需外网,延迟极低,安全性更高。
Q19:OpenClaw如何限制Multi-Agent的资源占用?
A:源码内置资源阈值配置,单网关限制最大Agent数量,每个Agent限制最大并发任务数、内存占用上限,超出阈值自动排队或拒绝新任务,防止系统过载。
Q20:OpenClaw多Agent的状态同步机制是什么?
A:各Agent状态独立存储,无全局状态同步,避免数据冲突;需共享数据时,通过MCP工具或指定共享目录实现,权限可控,符合本地优先与安全原则。
七、OpenClaw VS 其他框架 Q&A(20题,选型面试必问)
核心选型结论(面试直接套用):个人轻量化助手选OpenClaw,企业级定制开发选LangChain/LangGraph,学术验证选AutoGPT,多Agent协作编排选CrewAI,拒绝盲目选型,精准匹配场景! |
框架 | 核心定位 | 适配场景 | 部署门槛 | 资源占用 | 定制难度 |
OpenClaw | 本地优先轻量化Agent | 个人助手、本地工具、轻量化任务 | 极低,开箱即用 | 极低 | 低,技能化配置 |
LangChain/LangGraph | 企业级Agent开发框架 | 商业项目、定制化工作流、生产级部署 | 中高,需二次开发 | 中 | 高,灵活扩展 |
AutoGPT | 自主Agent学术标杆 | 算法验证、学术研究、概念演示 | 中 | 高 | 中,源码改造 |
CrewAI | 多Agent协作编排 | 团队式任务、多角色分工、复杂流程 | 中 | 中高 | 中,角色配置 |
本章聚焦四大框架对比,修正市面错误选型逻辑,每道题贴合面试真实提问场景,难度分级排布,共20题,背完直接应对选型类面试题。
基础级(Q1-Q5,面试开场选型必问)
Q1:OpenClaw和LangChain的核心区别是什么?
A:OpenClaw是开箱即用的成品化轻量化Agent,本地优先、无需编码、低资源占用,主打个人快速落地;LangChain是企业级开发工具链,需二次开发、支持云端部署、扩展性极强,主打商业项目定制,二者定位完全不同。
Q2:为什么个人轻量化助手优先选OpenClaw,而非CrewAI?
A:CrewAI主打多Agent团队协作,需配置多角色、工作流,资源占用高、配置繁琐;OpenClaw单Agent即可运行,本地部署、一键启动、无多余配置,完全适配个人日常助手、本地任务场景,轻量化优势碾压。
Q3:AutoGPT适合生产环境吗?为什么?
A:不适合!AutoGPT是学术研究型框架,设计初衷是验证自主Agent能力,存在资源占用高、稳定性差、安全机制薄弱、无完善权限管控等问题,仅适合实验室验证,不适合企业/个人生产落地。
Q4:LangGraph相比LangChain,核心优势是什么?
A:LangGraph是LangChain的升级工作流框架,支持循环、分支、状态管理,适合复杂多步骤、持续性Agent任务,企业级定制开发优先选LangChain+LangGraph组合,OpenClaw无此类复杂工作流需求。
Q5:CrewAI的核心竞争力是什么?
A:主打多角色Agent协作,模拟真实团队分工(产品、研发、运营),适合复杂团队式任务,是目前多Agent协作领域最易用的框架,OpenClaw暂不支持此类大规模多角色协作。
进阶级(Q6-Q10,技术面选型深度提问)
Q6:OpenClaw的本地优先特性,相比其他框架有什么不可替代的优势?
A:其他三大框架均偏向云端/服务端部署,数据易上传云端;OpenClaw全量数据本地存储、离线运行、隐私不泄露,适配个人隐私敏感场景、无外网环境场景,这是其他框架不具备的核心优势。
Q7:企业级定制开发为什么不选OpenClaw,而选LangChain?
A:企业级需求需对接内部系统、多用户权限、高并发、云端扩容、二次开发集成;OpenClaw定位轻量化个人场景,扩展性有限、无完善企业级权限与并发管控;LangChain生态完善、支持云端部署、可深度定制,完全适配企业需求。
Q8:OpenClaw可以替代AutoGPT做自主任务吗?
A:日常轻量化自主任务完全可以,且更优!OpenClaw启动快、资源占用低、安全可控,适合日常文件处理、消息收发、本地命令执行;AutoGPT适合极端复杂自主任务验证,但实用性、稳定性远不如OpenClaw。
Q9:四大框架的学习成本排序是怎样的?
A:从低到高:OpenClaw(零基础开箱即用)<CrewAI(角色配置即可)<AutoGPT(源码理解)<LangChain/LangGraph(全栈开发能力),个人用户首选OpenClaw,学习成本几乎为零。
Q10:OpenClaw和CrewAI在多Agent场景的差异是什么?
A:OpenClaw多Agent是轻量级隔离单Agent共存,无复杂协作,适合多独立助手;CrewAI是多角色协同完成单一复杂任务,有明确分工、工作流、信息交互,适合团队级任务,二者场景完全不同。
高级(Q11-Q15,大厂选型深度面)
Q11:OpenClaw的技术架构,相比LangChain有什么精简设计?
A:OpenClaw剔除了企业级冗余模块,无复杂中间件、无云端依赖、无多余扩展接口,采用“网关+核心引擎”极简架构,启动速度快、资源占用低,牺牲部分扩展性换轻量化;LangChain保留全量扩展模块,适配复杂定制。
Q12:为什么学术验证首选AutoGPT,而非OpenClaw?
A:AutoGPT是自主Agent的开山之作,学术论文引用量极高,源码更贴近原生自主Agent算法,适合研究Agent推理、自主决策逻辑;OpenClaw是工程化落地框架,侧重易用性,算法层面无学术研究价值。
Q13:OpenClaw可以和LangChain联动使用吗?
A:可以!通过MCP协议对接,OpenClaw作为本地执行端,LangChain作为云端工作流编排端,实现“云端规划+本地执行”的混合架构,兼顾企业级工作流与本地隐私安全。
Q14:CrewAI相比LangGraph多Agent,优势是什么?
A:CrewAI上手门槛更低,无需编写复杂代码,通过配置文件定义角色、目标、工具即可;LangGraph需编码定义工作流,灵活性更高但门槛高,CrewAI适合快速搭建多Agent原型,LangGraph适合生产级复杂协作。
Q15:选型时,如何根据用户群体快速确定框架?
A:面试标准答法:个人用户/本地隐私场景→OpenClaw;企业商业项目/定制开发→LangChain/LangGraph;学术研究/算法验证→AutoGPT;多角色团队任务/复杂协作→CrewAI,严格按场景匹配,不盲目选热门框架。
源码级(Q16-Q20,源码面选型延伸)
Q16:OpenClaw的源码精简性,体现在哪些方面?
A:源码无冗余依赖,核心代码量远低于其他框架,采用TypeScript单线程轻量化设计,无复杂多线程、分布式模块,专注本地单Agent执行,编译打包体积小、运行效率高。
Q17:LangChain的生态优势,对企业选型的影响是什么?
A:LangChain支持海量模型、工具、向量库、云平台适配,企业可快速对接现有系统,二次开发成本低,社区支持完善,生产环境问题易解决,这是OpenClaw生态无法比拟的。
Q18">:AutoGPT的源码缺陷,导致生产环境无法落地的核心问题?
A:源码无完善沙箱机制、权限管控薄弱、无任务中断优化、内存泄漏严重,自主执行时易失控、占用大量系统资源,无法满足生产环境稳定性与安全性要求。
Q19:CrewAI的多Agent协作源码逻辑,和OpenClaw多Agent的区别?
A:CrewAI源码内置角色分配、任务拆解、信息共享、结果汇总模块,多Agent间可主动通信;OpenClaw多Agent源码仅做进程隔离,无主动通信模块,各Agent独立运行,无协作逻辑。
Q20:OpenClaw未来是否会拓展企业级能力?
A:官方愿景聚焦本地优先、轻量化、安全易用,不会向LangChain式企业级框架转型,未来会优化本地多Agent、安全机制,不会涉足复杂云端定制、高并发企业场景,保持自身定位。
八、安全与Guardrails Q&A(易忽略加分项)
核心考点(面试加分必背):2026年Agent面试隐性加分点,自主Agent三大核心风险=提示注入+权限过大+数据泄露;OpenClaw内置三大安全机制=配对认证+沙箱隔离+权限最小化,答出细节直接拉开分差! |
本章修正市面Prompt Injection、沙箱机制的细节错误,聚焦安全考点,每道题均为面试易忽略的加分题,难度分级排布,共20题,精准覆盖安全类提问。
基础级(Q1-Q5,安全基础必问)
Q1:自主Agent的三大核心安全风险是什么?
A:三大核心风险,也是面试必答点:
1)提示注入(Prompt Injection):恶意指令绕过系统提示,操控Agent执行违规操作;
2)权限过大:Agent拥有超出需求的系统权限,误操作/恶意操作破坏系统;
3)数据泄露:本地数据、API密钥、隐私信息被非法窃取或上传云端。
Q2:什么是提示注入(Prompt Injection)?
A:攻击者通过输入恶意提示词,覆盖或绕过Agent内置的系统提示规则,诱导Agent执行原本禁止的操作(如删除文件、泄露密钥、执行危险命令),是Agent最常见的安全漏洞。
Q3:OpenClaw的配对认证安全机制,作用是什么?
A:OpenClaw专属安全机制,首次启动需完成设备配对认证,仅授权设备可操控Agent,拒绝陌生设备、陌生消息来源的指令,从入口阻断未授权访问,防止外部恶意指令注入。
Q4:权限最小化原则在Agent安全中的作用是什么?
A:Agent仅拥有完成任务所需的最低权限,禁止授予全局管理员、系统核心目录读写等高危权限,即使被恶意注入,也无法执行高危操作,最大限度降低安全风险。
Q5:OpenClaw如何防范数据泄露?
A:本地优先设计,所有数据、密钥、会话记录均存储在本地~/.openclaw/目录,默认禁止上传任何数据到云端,无云端数据传输环节,从根源杜绝数据泄露风险。
进阶级(Q6-Q10,安全加分考点)
Q6:修正常见错误:沙箱机制不是单纯隔离,OpenClaw沙箱的核心作用是什么?
A:市面常见错误表述为“沙箱是隔离运行环境”,正确定义:OpenClaw沙箱是读写权限隔离+路径限制+软链接拦截的安全容器,仅允许访问Workspace目录,禁止访问系统目录、外部文件,阻断沙箱逃逸,防止Agent非法操作宿主系统。
Q7:OpenClaw如何防范提示注入攻击?
A:多重防护:1)系统提示词固化,优先级高于用户输入;2)恶意指令检测,拦截删除、格式化、密钥提取等高危指令;3)配对认证拦截陌生指令;4)危险工具需手动开启,默认禁用。
Q8:Agent权限过大的危害,相比普通软件有什么不同?
A:普通软件权限过大需人工操作,Agent具备自主执行能力,权限过大时,即使是误判或轻微注入,也会自主执行高危操作,危害呈指数级放大,远超普通软件权限漏洞。
Q9:什么是间接提示注入?OpenClaw如何防范?
A:间接提示注入是攻击者将恶意指令藏在文件、网页等外部数据中,Agent读取后被操控;OpenClaw通过沙箱限制外部文件读取范围,读取后做指令清洗,禁止外部数据覆盖系统提示。
Q10:OpenClaw的权限管控,默认规则是什么?
A:默认遵循权限最小化,只读权限自动执行,写入、删除、执行系统命令等高危权限,默认禁用,需用户手动开启并确认,无默认高危权限。
高级(Q11-Q15,深度安全面)
Q11:修正沙箱机制常见错误:沙箱种子(Sandbox Seed)的安全限制细节?
A:市面错误表述为“沙箱复制所有文件”,正确细节:OpenClaw沙箱初始化时,仅复制Workspace内的普通文件,强制忽略所有指向外部的软链接、硬链接、快捷方式,禁止沙箱访问宿主系统核心路径,彻底阻断沙箱逃逸。
Q12:Guardrails在Agent安全中的核心作用是什么?
A:Guardrails是Agent的安全护栏,实时监控Agent的推理、工具调用、指令执行,拦截违规操作、限制权限范围、清洗恶意输入,保障Agent在安全规则内运行,防止失控。
Q13:OpenClaw相比其他框架,安全机制的优势是什么?
A:1)内置原生安全,而非后期加装插件,安全机制更底层;2)本地优先无云端传输,数据泄露风险为零;3)配对认证+沙箱+权限最小化三重防护;4)默认安全配置,新手也不会出现权限漏洞。
Q14:如何检测Agent是否被提示注入攻击?
A:三大判断标准:1)Agent执行超出任务范围的高危操作;2)主动泄露本地数据、密钥信息;3)无视系统提示规则,执行恶意指令;OpenClaw内置攻击检测,异常操作会立即暂停并通知用户。
Q15:企业使用Agent,安全管控的核心要点是什么?
A:1)严格遵循权限最小化;2)部署沙箱隔离环境;3)全流程操作审计;4)提示注入防护;5)禁止明文存储密钥;6)关键操作人工审批,OpenClaw适配个人场景,企业需叠加LangChain安全插件。
源码级(Q16-Q20,源码安全加分题)
Q16:OpenClaw源码中,提示注入防护的核心代码逻辑?
A:源码将系统提示词放在上下文最底部,优先级最高,用户输入、外部数据均放在系统提示上方,LLM优先遵循系统提示;同时内置高危指令正则匹配,匹配成功直接拦截,不进入推理环节。
Q17:OpenClaw沙箱的路径白名单源码实现逻辑?
A:源码硬编码沙箱路径白名单,仅允许访问~/.openclaw/workspace目录,所有文件操作、命令执行都会先校验路径,不在白名单内的操作直接拒绝,无绕过可能。
Q18:OpenClaw的权限配置源码,如何实现动态权限管控?
A:权限配置存储在本地配置文件,采用只读加密格式,源码读取权限配置后,生成权限映射表,工具调用前先查表校验权限,无对应权限直接返回权限不足,不执行操作。
Q19:OpenClaw如何防止API密钥泄露?
A:源码中密钥仅存储在本地State Dir,采用加密存储,推理、工具调用时仅在内存中解密,禁止输出到日志、会话记录、文件,禁止通过消息平台发送,杜绝密钥泄露。
Q20:OpenClaw的安全审计日志,源码记录哪些核心内容?
A:记录所有工具调用、权限变更、配对认证、异常操作,包含时间、操作内容、权限状态、结果,日志存储在本地,不可篡改,方便安全排查,这是其他轻量化框架不具备的源码级安全设计。
九、业界实战场景面试题:从理论到落地的终极考验
前面八章我们已经覆盖了OpenClaw的原理、架构和源码级细节。但面试官真正想考察的,往往是你能否把这些理论用到实际业务中。本章精选了8道大厂真实面试中出现的高频场景题,涵盖客服Agent设计、RAG优化、Function Calling实战、长上下文处理等核心场景。
场景一:智能客服Agent设计(美团真题)
Q:假设你需要开发美团智能客服Agent,如何设计多轮对话流程?
【面试官点评】这道题看似开放,实则考察的是Context Engineering思维——把正确的信息在正确的时机喂给模型,比让模型自己去想要重要一万倍。
参考答案:
我的设计思路是采用Multi-Agent架构 + 分层容忍度,而不是传统的对话树。
1. 架构设计
用户输入 → 意图识别Agent→ 分发给领域Agent(订单/物流/酒店/售后)→ 主Agent统一输出
意图识别Agent:负责听懂用户要什么,判断调用哪个领域Agent
领域Agent:每个Agent只掌握自己领域的工具和数据(订单查询、物流跟踪、退改规则等)
主Agent:汇总信息,生成最终回复
2. 敏感操作的分层容忍度
这是客服Agent设计的关键——越敏感的操作,越不能让AI说了算:
3. 复杂任务的分解策略
当遇到复杂问题(如行程规划),不能让模型一口气跑完全程:
第一步:调用工具查询关联线路库
第二步:输出行程骨架(第几天、去哪里、玩什么)
第三步:基于骨架,精准查询具体交通班次、酒店实时价格
第四步:合并结果返回用户
这种分步执行的方式,能显著降低幻觉率,同时提升响应速度。
4. 弦外之音的识别
当用户说不清楚要什么时,需要结合历史订单、会话历史综合判断。如果还不清楚,就给出选项引导:
“您的订单已发货,可选:1.退货退款 2.仅退款 3.联系人工。”
就像问朋友“今晚吃啥”大概率得到“随便”,但换成“火锅还是烧烤”就能快速收窄问题。
场景二:Function Calling实战(阿里高频题)
Q:(代码题)请解释OpenAI的Function Calling机制,并写一段Python代码模拟“库存查询”工具的Schema定义。重点说明如何防止Agent乱调用工具。
【面试官点评】这道题考察的是你是否真的写过代码,还是只在低代码平台上拖拽。Schema的定义质量直接决定了Agent的“智商”。
参考答案:
Function Calling的本质是意图识别 → 参数提取。LLM并不直接运行代码,而是分析用户意图,输出JSON对象,告诉后端应该运行哪个函数以及参数是什么。
防止乱调用的关键技巧:在参数的description中加入“负向约束”(什么情况下严禁调用)
# 定义工具的 Schema,这是给 LLM 看的“说明书”tool_schema = {"type": "function","function": {"name": "query_inventory","description": "查询工厂仓库中特定零部件的实时库存数量。当用户询问'还有多少个XX'或'XX有货吗'时调用此工具。","parameters": {"type": "object","properties": {"part_id": {"type": "string","description": "零部件的唯一物料编码,例如 'A-101-X'。**注意:如果用户只提供了模糊名称(如'那个红色的阀门'),严禁调用此工具,应先追问用户获取精确编码。**",},"warehouse_zone": {"type": "string","enum": ["Zone_A", "Zone_B", "All"],"description": "指定查询的仓库区域,默认为 'All'。Zone_A 为原材料库,Zone_B 为成品库。",}},"required": ["part_id"]}}}
关键点解析:
description字段必须写得非常详细,它实际上是给模型的System Prompt在
part_id的描述中明确加入“模糊名称严禁调用”,这是负向约束的关键实践通过
enum限制可选值,避免模型生成不在范围内的参数
场景三:海量数据处理(工业场景题)
Q:在处理海量工业日志(CSV格式,10GB+)时,Python脚本如何避免内存溢出(OOM)?
参考答案:
这是数据工程的基本功,也是AI智能体运营工程师必须掌握的技能,因为我们经常需要清洗数据给AI训练。
核心原则:拒绝一次性全量加载,采用流式处理。
方案一:生成器 + 分块读
import pandas as pddef process_large_log(file_path):"""生成器函数:像流水线一样逐块处理数据"""# 使用 chunksize 分块读取,每次只读 1000 行到内存reader = pd.read_csv(file_path, chunksize=1000)for chunk in reader:# 数据清洗逻辑clean_chunk = chunk.dropna() # 删除空值# 将处理好的数据块 yield 出去yield clean_chunkdef main():source_file = "machine_log_2026.csv"for clean_data in process_large_log(source_file):# 逐块写入数据库或文件save_to_db(clean_data)print(f"已处理数据块... 内存占用稳定")if __name__ == "__main__":main()
这种写法可以在8GB内存的笔记本上,轻松处理100GB的日志文件。
方案二:对于更复杂的需求,可以考虑:
使用Dask或Vaex等分布式计算框架
将数据导入数据库,用SQL进行增量处理
使用PySpark进行真正的分布式处理
场景四:RAG文档切分优化
Q:RAG系统中,文档切分的粒度如何选择?切分太长或太短有什么副作用?
【面试官点评】文档切分是RAG效果好坏的决定性因素。很多只看教程的人只知道向量检索,但在工业实战中,纯向量检索往往不够用。
参考答案:
1. 切分不当的副作用
2. 最佳实践
按语义切分:优先按段落、Markdown标题进行切分,而不是机械地按字符数切分
重叠切分 (Overlap):设置10%-20%的重叠窗口。例如chunk 1是1-500字,chunk 2是450-950字,确保句子不会被从中间强行截断
实战数值:处理技术手册时,通常设置为500-800 Tokens左右
3. 混合检索的必要性
在工业场景中,纯向量检索往往不够用:
实战必要性:在工业场景极其重要。因为工人既会说“那个编码器”(语义),也会报出精确的“A860-T301”型号(关键词)。
场景五:Agent评估体系
Q:如何评估一个Agent系统的好坏?与传统LLM评估有什么不同?
参考答案:
评估Agent比评估基础LLM更加复杂,因为Agent是动态执行的,而LLM只是静态输出。
1. 评估维度的差异
2. Agent专属评估指标
任务完成率:能否成功完成给定任务
步骤效率:完成任务所需的ReAct循环次数
Token消耗:成本效率(每任务消耗的Token数)
幻觉率:错误输出比例,特别是工具调用错误
鲁棒性:面对异常输入的容错能力
端到端延迟:从接收到回复的总时间
3. 过程指标同样重要
除了最终结果,还需要关注:
工具调用准确率
重试次数
是否需要人工介入
用户满意度(如NPS)
4. 评估方法
LLM-as-a-Judge:用GPT-4等模型评估Agent输出质量
人工评估:设计合理的评估准则和流程
红队测试:模拟真实攻击发现安全漏洞
场景六:工业场景下的幻觉治理
Q:在工业场景下,如何通过Prompt工程解决大模型的“幻觉”问题?
【面试官点评】面试官不希望听到“给它更多上下文”这种泛泛而谈的答案,而是希望听到具体的技术手段和工程化方案。
参考答案:
解决幻觉的核心在于“约束”和“接地”。在实际工程中,我们通常采用组合拳:
1. 结构化约束 (JSON Mode)
强制模型输出JSON格式,并在System Prompt中定义严格的Schema,可以有效遏制幻觉。
例如:在提取机床参数时,明确规定“转速”字段必须为Integer,且范围在0-20000之间。如果模型生成了"High Speed",Schema校验会直接报错,触发重试。
2. 思维链引导 (CoT)
要求模型在输出结论前,先输出思考过程:
Prompt示例:“请先列出你检索到的参考资料片段,解释为什么选择这些片段,最后再基于这些片段回答问题。”
这种方法能让模型的推理过程“显性化”,便于人工审核。
3. 知识库拒答机制
在Prompt中明确注入“不知为不知”的指令:
“如果你在参考资料(Context)中找不到答案,请直接回复‘不知道’,严禁编造或使用外部知识。”
4. Few-Shot Prompting
提供3-5个标准的“问题-答案”对作为示例,让模型模仿这种严谨的风格。对于非标工业数据清洗,Few-Shot的效果远好于复杂的指令说明。
5. Chain of Verification (CoVe)
让模型在输出答案后,自己生成验证问题来检查答案的正确性。如果自验证发现不一致,则修正答案。
场景七:月报生成系统的实战设计
Q:假设你要开发一个智能月报生成系统,如何解决“原始报告”与“决策层需求”之间的差异?
【面试官点评】这是某大厂实习面试的真实二面题目,考察的是业务理解能力和技术落地的结合。
参考答案:
这是项目的核心洞察,也是价值所在。原始报告(员工视角)和决策层需求之间存在显著鸿沟:
系统解决方案:三层转换机制
1. 语义提炼层用LLM将技术描述转为业务语言:
输入:“优化SQL查询,响应时间从2s降至200ms”输出:“提升数据查询效率,用户体验显著改善”
2. 价值映射层构建“技术动作 → 业务指标”映射表:
生成时自动关联指标,如“本次优化预计提升QPS 15%”。
3. 结构化聚合层按高管关心的维度重组内容:
## 核心成果- **效率提升**:数据查询响应时间↓90%- **风险控制**:修复3个高危安全漏洞## 下一步计划- 推进XX项目上线(预计Q2贡献GMV 500万)
效果:管理层反馈“终于能快速抓住重点”,跨团队汇报效率提升60%。
场景八:长上下文与上下文丢失问题
Q:在Agent推理过程中,“推理断层”“结果与目标偏离”是常见问题。请结合具体技术说明如何解决?
参考答案:
“推理断层”通常源于上下文窗口限制和记忆丢失。以下是几种解决方案:
1. Compaction机制
OpenClaw的做法是:当会话token接近contextWindow - reserveTokensFloor时,触发auto-compaction。Compaction前先执行Memory Flush,强制Agent将关键状态写入硬盘文件(MEMORY.md),再进行压缩总结。
2. 分层记忆架构
memory/YYYY-MM-DD.md) | ||
MEMORY.md) |
3. 混合检索
将记忆切分为chunk,采用向量检索 + 关键词匹配的混合方式,快速精准调取相关记忆。
4. 分步执行
对于复杂任务,不要试图一步到位:
Plan-and-Solve:先生成完整计划,再逐步执行
ReAct + 自检:每步执行后检查是否偏离目标,必要时回退重试
5. Steering while streaming
当Agent正在流式推理时,用户发送新消息来“转向”Agent的注意力。OpenClaw在steer模式下,每次tool call后检查队列,及时响应新消息,避免沿着错误路径跑完全程。
面试官终极点评
这8道题覆盖了从架构设计到代码实现,从数据处理到业务理解的完整链条。真正的AI Agent工程师不仅要懂八股文,更要能解决实际问题:
客服Agent考的是Context Engineering和风险分层
Function Calling考的是Schema设计的精细度
RAG优化考的是对检索本质的理解
幻觉治理考的是工程组合拳的运用
把这些场景题吃透,你离Offer就不远了。
Openclaw,只在中国火了?
https://zhuanlan.zhihu.com/p/2013287262197133860
OpenClaw + AI Agent 面试八股文:背完这篇,你懂的比面试官还多!
https://zhuanlan.zhihu.com/p/2013536456132554764
从 Clawdbot 到 Moltbot 再到 OpenClaw:这个让 Mac Mini 卖断货的 AI 助手,到底有多野?
带你实现一个Agent,从Tools、MCP到Skills,从理论到代码,干货满满
OpenClaw GitHub 仓库 - GitHub OpenClaw: Complete Guide to the Open-Source AI Agent - Milvus Blog OpenClaw Wikipedia - Wikipedia OpenClaw: Deploying an Open-Source AI Agent Framework - Medium How OpenClaw Works: Understanding AI Agents Through a Real Architecture - Medium OpenClaw Explained: How the Hottest Agent Framework Works - Medium What Security Teams Need to Know About OpenClaw - CrowdStrike OpenClaw AI Agent Masterclass - HelloPM OpenClaw: Ultimate Guide to AI Agent Workforce 2026 - o-mega 大模型-Agent 面试八股文,简单背一背 (入门级) - 知乎 OpenClaw 智能体 - 知乎 OpenClaw 最强军火库:精选 2868 个 skills - 知乎 2026年做 Agents 应该看这篇全面的技术综述 - CSDN 2026 AI Agent 工程化圣经 - CSDN OpenClaw 2026 终极指南 - CSDN AI Agent 简介 - 菜鸟教程 AI Agent万字长文总结:规划, 工具, 执行, 记忆 - 53AI 开发者欢呼,普通人迷茫:OpenClaw之后 - InfoQ 上海一群青年,造了个学术版OpenClaw - 量子位 OpenClaw 平替产品全景对比 - 53AI 25 Advanced Agentic AI Interview Questions for 2026 - AEM Institute 30 Agentic AI Interview Questions and Answers - Analytics Vidhya Top Agentic AI Interview Questions and Answers - GeeksforGeeks 10 Essential Agentic AI Interview Questions - KDnuggets Top 30 Agentic AI Interview Questions - DataCamp Function Calling with LLMs - Prompt Engineering Guide Tool Calling Explained: The Core of AI Agents - Composio ReAct 框架 - Prompt Engineering Guide 大模型Agent之ReAct核心原理解析 - 知乎 Agent 的九种设计模式 - 53AI MCP vs A2A: Protocols for Multi-Agent Collaboration 2026 - OneReach What Is Agent2Agent (A2A) Protocol? - IBM Top AI Agent Protocols in 2026 - GetStream OpenClaw vs LangChain: 2026 Agent Framework Comparison - Fast.io Memory - OpenClaw - OpenClaw Docs OpenClaw Permanent Memory System - OpenClaw API What are OpenClaw Skills? A 2026 Developer’s Guide - DigitalOcean Gateway Architecture - OpenClaw - OpenClaw Docs AI Agent Architecture with Diagrams - Designveloper OpenClaw Deconstructed: A Visual Architecture Guide - Global Builders Club

